End of The Road: Last Remarks on MPI and GASPI.
Hi again! In my last post I mentioned how we parallellized the decision tree algorithm with MPI and how much performance gain we obtained with increasing number of cores. In this post I would like to briefly discuss how the performance is further improved.
MPI vs GASPI
As shown in the performance plots in my previous post, time spending for synchronization, is an important issue for a parallel program. In MPI’s standard send/receive commands, processor cores blocks each other during the communication, which means that processors should wait each other until the message is successfully left by the sender and delivered to the receiver. This kind of communication strategy is called two-sided communication.
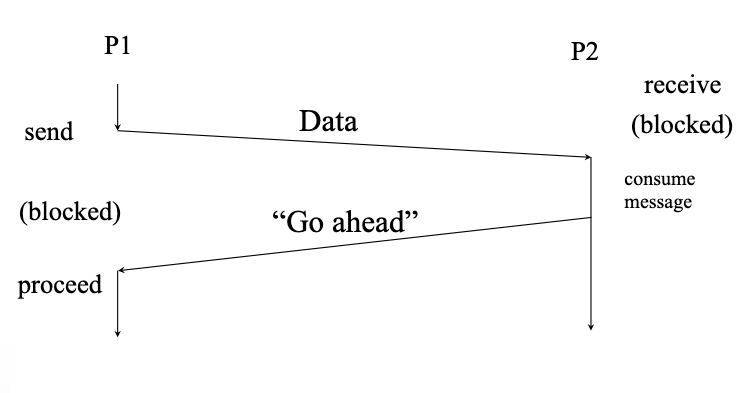
We can’t completely get rid of communication overhead, but we can overlap communication and computation task by using a different parallelization paradigm.
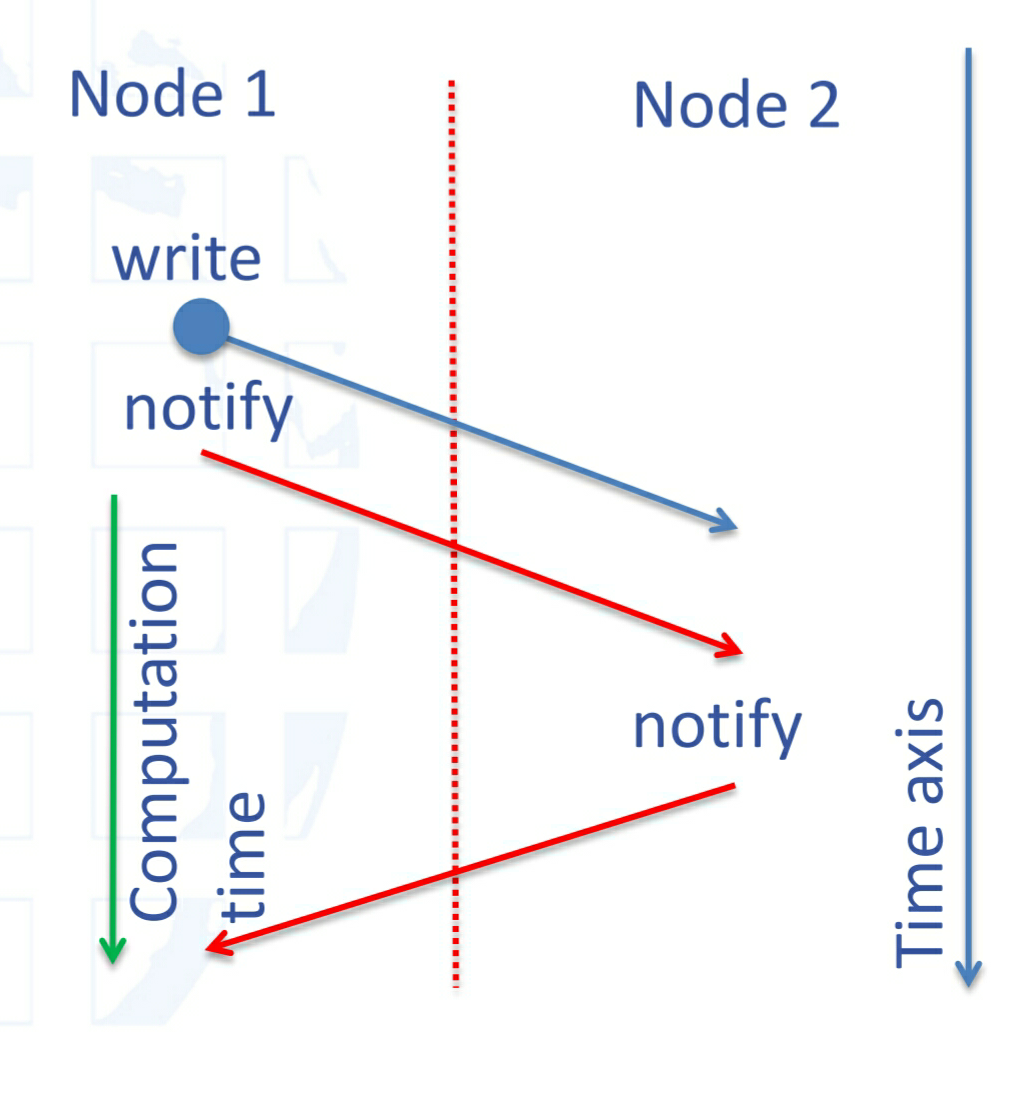
GASPI (Global Address Space Program- ming Interface) is considered as an alternative to MPI standard, aiming to provide a flexible environment for developing scalable, asynchronous and fault tolerant parallel applications. It provides one-sided remote direct memory access (RDMA) driven communication in a partitioned global address space. This definition may be hard to grasp, but what we should focus on GASPI is its capability of providing one-sided communication environment without tough sycnronization requirements. One-sided communication allows a process to make read and write op-erations on another processor’s allocated memory space without the participation of other processors. Unlike two-sided communication, the processor whose memory is being accessed, continues its job without any interruption. This means that the processors continue their computations alongside with their communication.
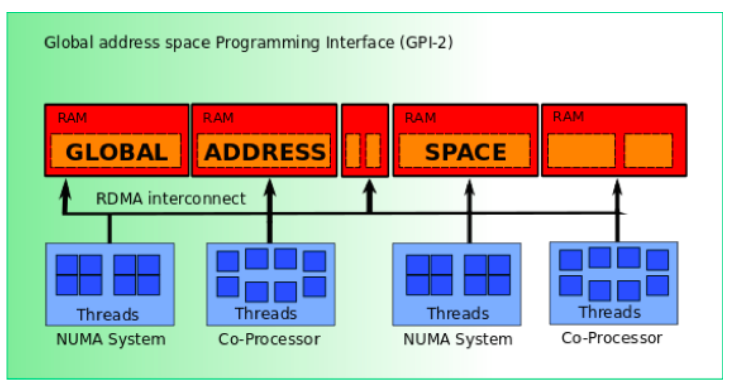
GPI-2 is an open source programming interface allowing implementation of the GASPI standard. It is compatible with C and C++ languages to develop scalable parallel applications. The working principle of GPI-2 is demonstrated in figure below.
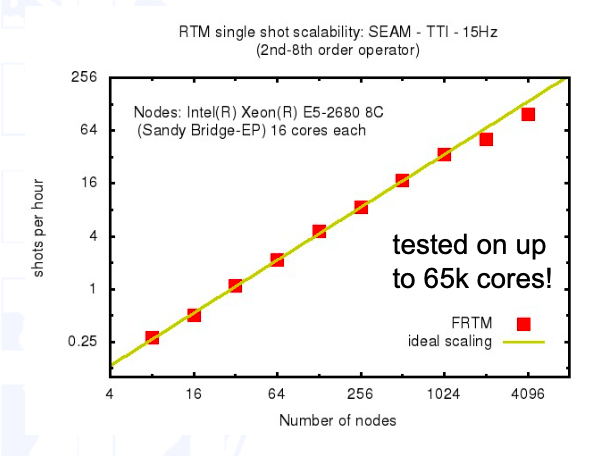
Unfortunatelly, we didn’t have enough time to finilaze the implementation of GPI-2 for our algorithm, so I can’t show you the performance results right now. But performance plot of GPI-2 (below) taken from its official tutorial document (http://gpi-site.com.www488.your-server.de/tutorial/) shows that it really works.
Farewell
I hope that you learn from my posts. I guess now it is time to say goodbye. I would like to thank all the people make this organization happen.

Leave a Reply