Machine learning from the HPC perspective
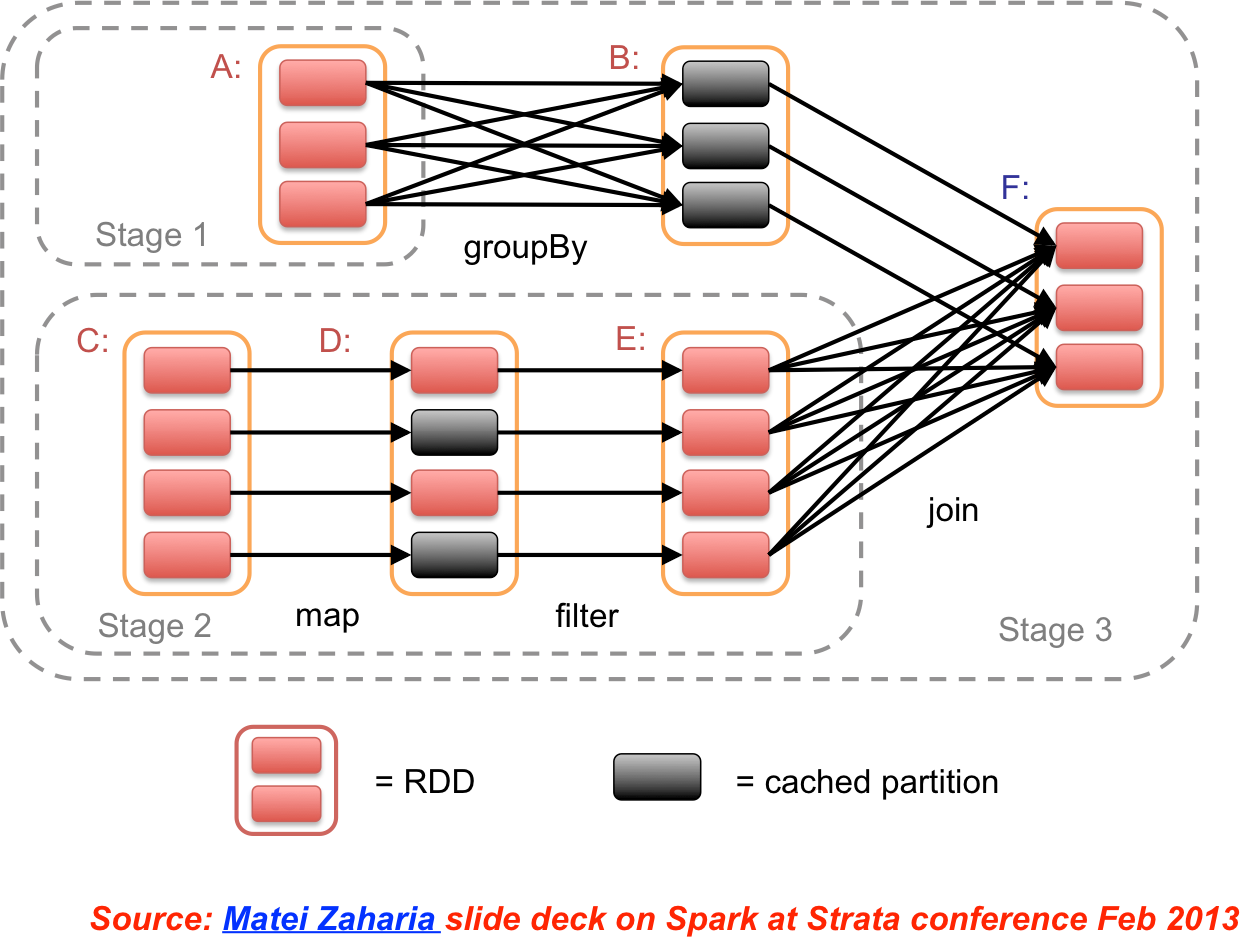
Project reference: 1808
This project is, to a large extent, a continuation of the last year’s SoHPC effort, where we demonstrated a notable increase of the efficiency of popular machine learning algorithms, such as K-means, when implemented using C/C++ and MPI – over those provided by Apache Spark MLlib.
The goal of the project remains the same: Demonstrate that “traditional” HPC tools are (at least) just as good, or even better, than the JVM-based technologies for big data processing – such as the Hadoop MapReduce or Apache Spark. There is no doubt about that performance advantages of C/C++ or Fortran compiled codes over those running on top of JVM (be it Java, Scala or other). The performance clearly is important, but not the only metrics to judge, which of the approaches is better. We also have to address other aspects, in which popular tools for big data processing such as the Apache Spark, shine – that is the run-time resilience and parallel, distributed data processing.
The problem of MPI run-time resilience is a vivid research field for a past few years and several approaches are now application ready. We plan to use GPI-2 API (http://www.gpi-site.com/gpi2) implementing GASPI (Global Address Space Programming Interface) specification, which offers (among other features) mechanisms to react to failures.
The parallel, distributed data processing in the traditional big data world is made possible using special filesystems, such as the Hadoop file system (HDFS) or other similar file systems. HDFS enables data processing using the information of data locality, i.e. to process data that is “physically” located on the compute node, without the need for data transfer over the network. Despite it is the many advantages, HDFS is not particularly suitable for deployment on HPC facilities/supercomputers and use with C/C++ or Fortran MPI codes, for several reasons. Within the project, we plan to explore other possibilities (in-memory storage / NVRAM, and/or multi-level architectures, etc.) and search for the most suitable alternative to HDFS.
Having a powerful set of tools for big data processing and high-performance data analytics (HDPA) built using HPC tools and compatible with HPC environments, is highly desirable, because of a growing demand for such tasks on supercomputer facilities.
Project Mentor: Doc. Mgr. Michal Pitonák, PhD.
Project Co-mentor: Mgr. Lukáš Demovič, PhD.
Site Co-ordinator: Mgr. Lukáš Demovič, PhD.
Learning Outcomes:
The student will learn a lot about MPI and GPI-2 (C/C++ or Fortran), Scala programming language, Apache Spark as well as ideas of efficient use of tensor-contractions and parallel I/O in machine learning algorithms.
Student Prerequisites (compulsory):
Basic knowledge of C/C++ or Fortran, MPI and (at least one of) Scala or Java.
Student Prerequisites (desirable):
Advanced knowledge of C/C++ or Fortran, MPI, Scala, basic knowledge of Apache Spark, big data concepts, machine learning, BLAS libraries and other HPC tools.
Training Materials:
- http://www.scala-lang.org
- http://spark.apache.org
- http://spark.apache.org
- http://nd4j.org/scala.html
- http://www.gpi-site.com/gpi2
Workplan:
- Week 1: Training.
- Weeks 2-3: Introduction to GPI2, Scala, Apache Spark (and MLlib) and efficient implementation of algorithm.
- Weeks 4-7: Implementation, optimization and extensive testing/benchmarking of the codes.
- Wweek 8: Report completion and presentation preparation.
Final Product Description:
The expected result of the project is a resilient (C/C++ or Fortran) GPI-2 implementation of several popular machine learning algorithms on a data locality-aware parallel filesystem, yet to be chosen. Codes will be benchmarked and compared with the state-of-the-art implementations of the same algorithms in Apache Spark MLlib or other “traditional” big data/HDPA technologies.
Adapting the Project: Increasing the Difficulty:
The choice of machine learning algorithms to implement depends on the student’s skills. Even the simplest algorithms are difficult enough to be implemented towards the run-time resilience.
Adapting the Project: Decreasing the Difficulty
Similar to “increasing difficulty”. We can choose the simplest machine learning algorithms or, in the worst case, sacrifice either the requirement of resilience or the use of a next generation files system.
Resources:
The student will have access to the necessary learning material, as well as to our local IBM P775 supercomputer and x64 infiniband clusters. The software stack, we plan to use, is open source.
Organisation:
Computing Centre of the Slovak Academy of Sciences
