SLAE, preconditioners, optimisation
Hello again! It’s time for an update blog! Last time I shared some thoughts on the training week and the initial idea behind the project. Naturally, a lot has evolved since then and here I will try to explain how.
First of all, it is necessary to define the problem that we are trying to solve. And again, I will use the example from Earth Sciences. Imagine you are on land and you set up an experiment which involves using a controlled source of seismic waves (dynamite for example) and a line of receivers. The goal is to find the structure of the subsurface. You proceed with the explosion and gather wavefield data from your sensors. You use it to make cross-sections, such as the image below. The issue is that the scale is time and not distance (which we want). In order to convert it, you can think of a very simple equation: distance = velocity x time.
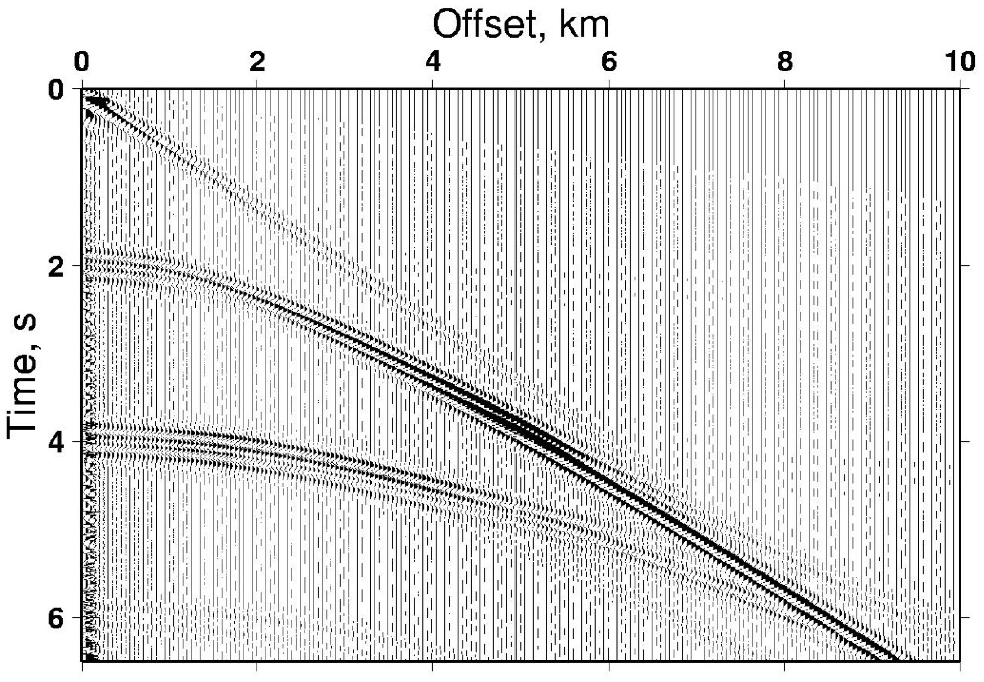
Seismic section. Source: Imperial College London
In order to constrain structural features (related to distance, not time), we can adopt a simple approach. We can discretise subsurface into a grid. Each box will represent one value of velocity and have defined dimensions. We take the inverse approach of trying to match the sum of distance/velocity per box over the whole path of seismic wave to the observed arrival times. This can allow us to determine what the actual structure of geological layers is.
This problem and many other similar ones can be adapted to the following form: Ax = b. This is the, so called, System of Linear Algebraic Equations (SLAE). As you can already imagine, there is a lot (!) of data involved, so any means of accelerating the computations are important. You would probably be quite disappointed if you tried to solve such problems living in pre-supercomputer era!
Moving on to our project, the approach we are using (and trying to optimise) is preconditioning. The idea is quite straightforward, we need to find a preconditioner for a given SLAE, a matrix which “simplifies” the problem when the system is multiplied by it. It can be thought of as an approximation of the inverse of matrix A. “Simplifies” means that it makes the problem more suitable for the solution methods, makes it converge faster to a solution. The hard thing about preconditioners is that there is no precise and established way of finding a good one for a particular problem. And this is where we come in. Our goal is to build an algorithm that can learn which parameter choice can lead to a good preconditioner. There is a lot it should do in a single iteration: perform random sampling or an optimisation procedure (depending on how far in the process we are), compute a preconditioner, compute a pure solution (without preconditioner) and the preconditioned solution. Over the past few weeks, we have been experimenting with different optimisation methods, including DQNs and Gaussian processes. We are yet to get our final results (which will hopefully look nice) that would be presentable. We’ll see what happens by the third and last update of this summer. Stay tuned!

Leave a Reply