Learning by trial and error
Hello! This is the final follow up on our project and luckily, we can now show off fancy looking plots from the results we’ve got.
We’ve settled for Gaussian processes (GP) as the method for performing optimisation. Additionally, we had to change the paradigm from considering matrix features (as described by Adrian here) to building our model for every individual matrix, due to added complexity in the first approach.
In essence, the algorithm is based on sampling the model, that is evaluating the system with a preconditioner computed with MCMCMI from a given set of parameters. As you can imagine, sampling is the most time-consuming and computationally intensive part of the algorithm and we do need to take numerous samples to meaningfully explore the parameter space. The expense is not so critical to us because we have headed towards the “parameter search” direction.
Samples are associated with a set of MCMCMI parameters (stochastic and truncation tolerances) and a reward value which has been defined as the ratio between the runtime of solving without preconditioner and with one. Given a number of samples, the code, iteratively, performs regression on them; computes an optimal set of parameters moving up the expected gradient towards a maximum of the GP distribution; takes a new sample guided by optimal parameters and strategies that avoid biased behaviour (e.g. getting stuck in a corner).
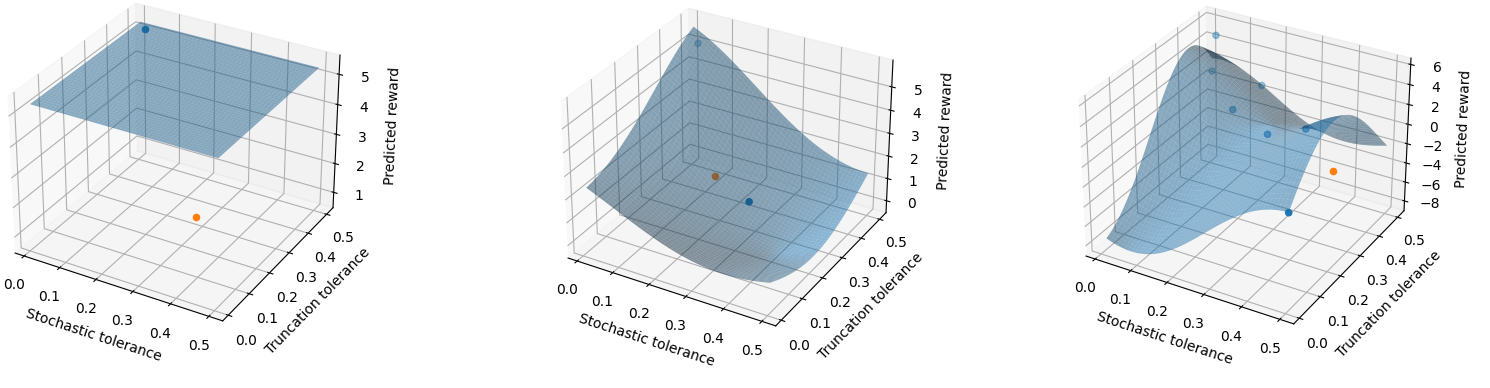
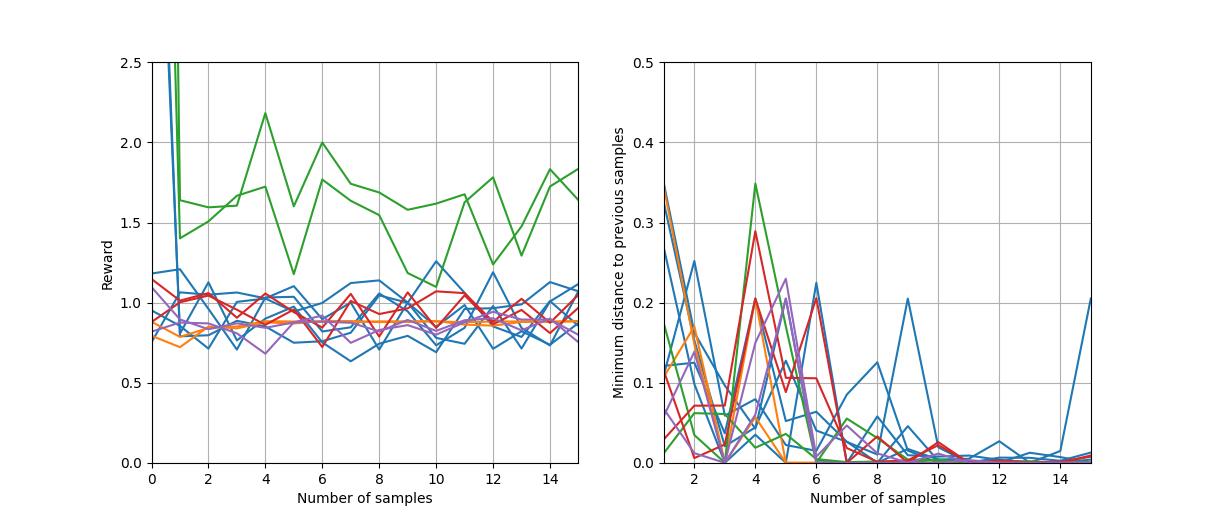
In the end, we’ve been able to match the data reasonably well, however discovered that our optimisation doesn’t lead to an observable improvement, but to an oscillating behaviour around the reward value of 1 (see Fig. 2).
Three issues have been highlighted:
- Outliers
- Overexploiting the model built from initial samples
- As sampling progresses and points gather in clusters, the model can get too smooth
If you’d like to read about this in more detail, see our report! And while you’re at it don’t miss the other reports from all the amazing projects this year!
To conclude, I’d like to thank the mentors for this project, Anton Lebedev and Vassil Alexandrov. This summer has been very interesting and really valuable for me in terms of getting experience of research and working with HPC systems. I gained more confidence in my coding skills and learned a lot. I would highly recommend this programme to anyone interested in HPC (even if you don’t know much about it and simply want to learn) and wish best of luck to whose who decide to apply for the next year! Bye!

Leave a Reply