So, what’s the right way to get in line?

Well that’s an odd question… you just file up in a queue obviously, or the shortest queue if there are multiple ones, and get in the back of such line. Well yes, that is one way to do it, and this way is what we are mostly used to in our daily lives, but as we will see in this post, that’s not always the best way to do it.
Queueing theory, a mathematical area developed to solely study waiting lines or queues, tells us that there are several ways to get in a queue, each one with its own benefits and costs. The one method that we are most used to, is called FIFO, short for first-in first-out, where the users are serviced on a first come first serve basis. Now, whilst this seems fair, this isn’t always the most convenient or efficient way to form a queue. Shortest Job First (SJF), builds a queue based on a user’s servicing time such that users with smaller jobs get serviced first. A job can refer to a multitude of things, think for example if you are in the grocery store, and you only want to buy a carton of milk, but the person in front of you has a whole shopping cart full, in the SJF scenario you could skip the person in front of you, and the cashier would service your job (i.e. make you pay for your single carton of milk) first. In SJF the average waiting time per person is decreased with respect to FIFO, but this scheduling of queue’s presents us with another problem called starvation, which means that the poor person with a full shopping cart of items might have to wait an undetermined amount of time before he gets to check-out. Another type of queueing type is based on the priority of users. Think of airports, where it doesn’t matter when a business class ticket owner arrives or how long it takes to service her, she gets priority and skips the line. These are just a few of the examples of scheduling algorithms used in queueing theory, this field can be studied much more in depth looking at the mathematics behind the arrival times of users, the average waiting times and servicing times.
Ok, great…. but what does all of this have to do with high performance computing (HPC)? I’m glad you asked, this in fact is a very big part of HPC and how clusters work. At Hartree Centre, different users, think master students, PhD students, staff, etc) can submit their programs to run on the cluster. As we saw in the previous post, these users have to submit an estimate of their running time such that the cluster can schedule the jobs in an appropriate manner, based on the scheduling algorithm chosen.
Hartree Centre uses the SLURM workload manager to schedule the cluster’s jobs. This is a flexible tool that allows the user, in this case the Hartree cluster, to decide how to best manage their scheduling algorithm. SLURM in fact lets the user decide how much weight to give to factors like job size, priority status, age of the job (which avoids the indefinite starvation of a job, i.e. at a certain point the shopping-cart full person gets priority) and more. All these factors can be modified at the discretion of the user, such that queueing can give more importance to any and all of these different aspects. The default scheduling algorithm for SLURM remains FIFO.
Apart from giving the SLURM user the power to give priority based on their needs, this is also important because it allows the cluster to be run efficiently, to consume less resources or energy if properly configured. To give a simple example, the figure below illustrates 4 jobs submitted to the cluster, in it we can see the difference between two scheduling algorithms on the left and right.
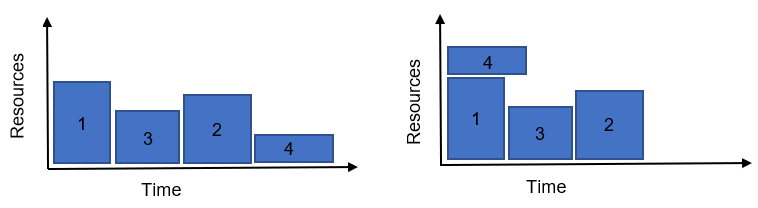
In the figure we can see the difference between what is commonly referred to as backfilling. In it, the 4th job is the longest job in the queue, but given that it needs fewer resources from the cluster, and that it doesn’t delay the 2nd or 3rd jobs, it can be back-filled.
This is some of the background theory I learnt the past week about the scheduling algorithms used in clusters and through SLURM. As mentioned in the previous post, these are effectively rendered inefficient if users don’t submit correct estimates of running times.
Stay tuned for the next blog post, where we will be exploring different regression methods and machine learning algorithms to predict more accurate running times to feed to the SLURM scheduler.

Leave a Reply