The convergence between High Performance Computing and Big Data

This Summer of HPC in Bratislava is coming to it’s end. A summer which has been full of adventures and amazing experiences, meeting great people and spending a lot of time working hard on the project and learning from it. We’ve been spending a lot of time on our projects but we’ve also had the time to do amazing trips, like a boating day at the Danube river. The trip took about 6 hours, and although it required a lot of effort, it was completely worth it.
We, getting a rest in the middle of the journey
Also, as result of this summer, I have created a video to allow everyone to learn about and understand what is High Performance Computing, what is Big Data, their applications and some other things, while also introducing some aspects of my project in a very popular manner, in such a way that it reaches the maximum amount of people, using very general content and a whiteboard-style animation video.
Project Results
We successfully implemented – as my previous post explains, the proposed algorithms with different traditional HPC approaches (MPI) and with renowned Big Data tools (Apache Spark), in order to measure the computational efficiency, as well as a fault-tolerant approach (GPI-2) which outperforms the efficiency of Apache Spark while still preserving all of its advantages.
We depicted the results for running K-Means with Apache Spark, first and second MPI methods and mixed MPI/GPI-2 method, with different number of cluster centers and maximum number of iterations, using the 1 million 2-dimensional dataset. We used 2 and 4 nodes for this benchmarking.
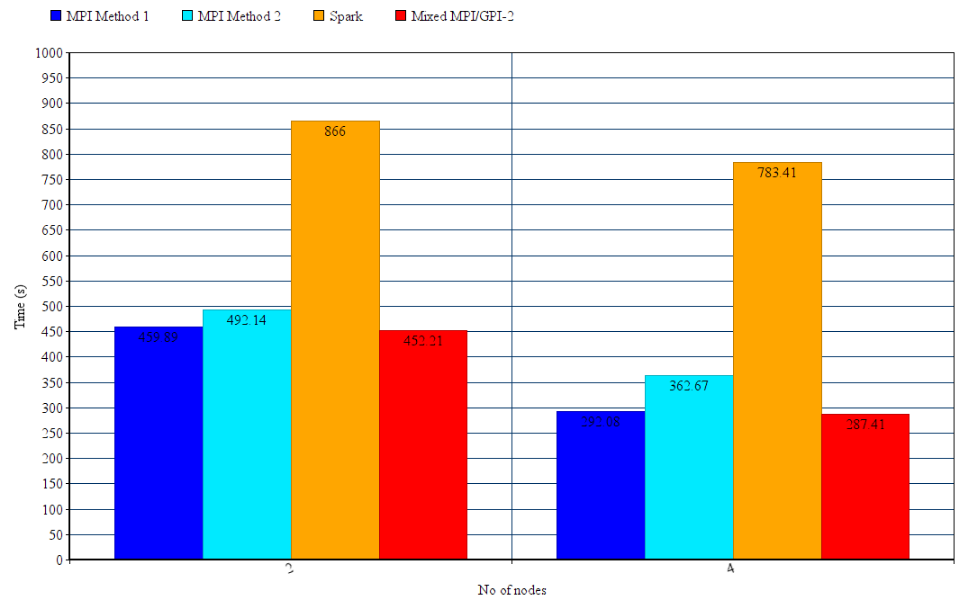
Execution time of K-Means on a varying number of nodes with 1 million points, 1000 centroids and 300 iterations over 1 million 2-dimensional points
This experiment was carried out for 1000 centroids and 300 iterations. Apache Spark, as expected works significantly slower, with a 2.5 time decrease in speed when compared to other approaches. The first MPI approach turned out to be slightly better in terms of computation time than the second MPI approach. Also, the Mixed MPI/GPI-2 method, even with the added fault-recovery capability, is slightly better than the second best implementation (the first MPI approach). GPI-2 features doesn’t add any appreciable delay in the execution due to the fact it uses, in the logical level, the GASPI asynchronous methodology to perform all the checkpoint savings and fault detections.
Future Plans
Although the progress of the project has ended up exceeding the initial goal, my mentor (Michal Pitoňák) and me, have more ideas in order to finish a scientific article about the work we’ve done with this project, so throughout this year we’ll continue working hand-by-hand to finish them.

Leave a Reply