UPDATE: Approval of heavenly-performing Turbo-Python?

Using the HPC clusters is not rocket science, but still you have to know how to do it. That’s exactly where we started before going into examining the velocity of our code and the two HPC systems ARCHER2 and Cirrus.
What code did we use to investigate its performance and to test the two HPC systems?
Our performance benchmark is an example from the Computational Fluid Dynamics (CFD). It simulates a fluid flow in cavity and shows the flow pattern. On a two-dimensional grid, the computer discretises partial differential equations to approximate the flow pattern. The partial differential equations, describing a steam function, are solved by using the Jacobi algorithm. It can be described as an iterative process which converges to a state with an approximated solution. Every iteration until the stable state adds precision to the results. Additionally, increasing the grid size leads to a result with higher precision but is also more computational intensive.
How does is it look like?
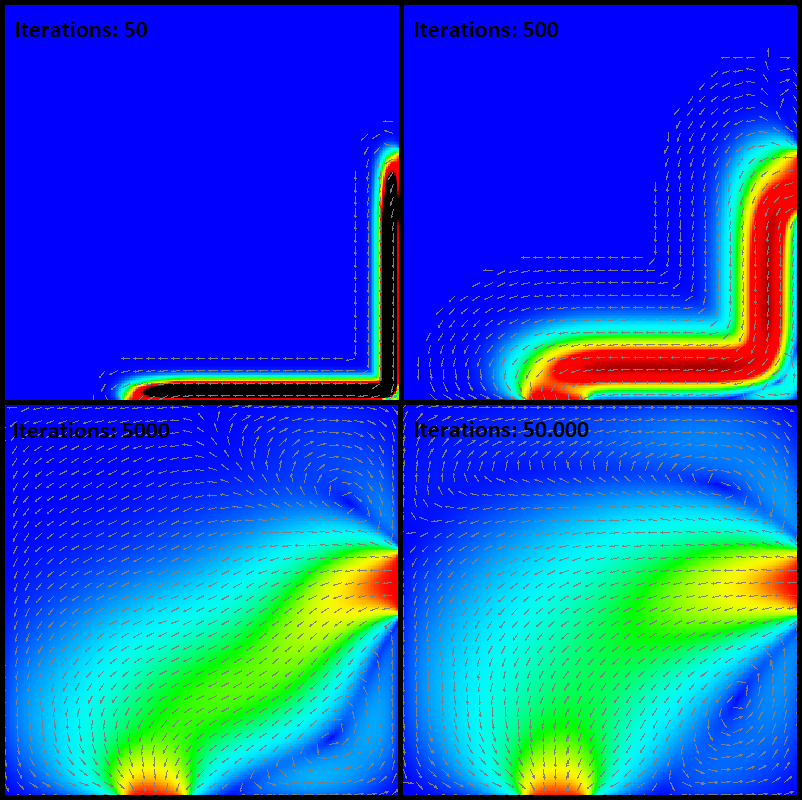
What language did we deal with and what did we focus on?
C, Fortran and Python. The code in C and Fortran was already there. Hence we had to translate C or Fortran into Python and make sure that they do the same. We focused on Python as it is a widely used language in science and more and more often used on HPC systems for running code. In comparison to C and Fortran as you might know, Python is slow: The readability and the dynamic typing – defining the variable type in the runtime – slows down the performance and makes Python unattractive for complex calculations with big problem sizes. At the same time, Python is popular and has a big community which means that there are solutions!
What did we use to improve the performance of Python?
- Optimise: Numerical Python, named Numpy, is a specialized package which is optimized. (Surely, in the end of the project we can post some evidence!)
- Divide your problem: MPI is a typical way to parallelize code. mpi4py is a package made for this purpose in Python.
- Parallelize it but with much more cores: Apply your problem to GPUs
What did we measure and how?
The core of the algorithm is an iterative process. The algorithm improves with every iteration the approximation of the fluid dynamic, meaning that every iteration processes the same numeric calculation. Therefore the mean of the time of iteration provides us with information of the performance.
We coded. We tried out. We played around with alternatives. What to expect from coding on HPC Systems and what performance improve you can achieve with Python, NEXT TIME we will provide you with all the insights!
PhD candidate at University of Limerick | DAFINET group | carving out a network theory of attitudes

Leave a Reply