Episode 3: The Chamber of Secrets.

Many hands make light work (or maybe just Lumos if you’re a wizard). How about many processors?
Howdy, Friends!

I hope you are all doing great and that you are enjoying your summer (Or any season… Future applicants of SoHPC20 triggered… )
I am getting the best of my time/internship here in Bratislava. I am learning a lot about programming, Machine Learning, HPC, and even about myself! In parallel with that (seems like HPC is a lifestyle now), I am really enjoying my free time here visiting Bratislava and other cities around!
I can hear you saying “Learning about programming? And herself? What is she talking about? Well, humor me and you’ll understand!
Programming
Well, this is something I wasn’t expecting to be this important, but it is actually an important feature!
I have not programmed a lot in C lately and got more used to Object Oriented languages like C++ and Python. I found myself here programming in C an algorithm that my brain was designing only in an “object oriented” way.
So I had to adapt to the C language constraints while implementing my regression tree. This took some time and I had some delays, so I am not on time regarding what you saw here but the steps are the same and I am trying to catch up. Hopefully my final product will meet the expected requirements…
Machine Learning
So, as I told you in my last post (Come ooon, you’re telling me that you can’t remember the blog post you read 3 weeks ago? Shame… on me, for not posting for this long!)…
Excuse: I was really focused on my code’s bugs……..
…I implemented a decision tree. The idea of this algorithm is to find a feature (a criteria) that will help us “predict” the variable we study. As an example we can create our own (super cool but tiny) dataset as follows:
| IndependentParts | LinesRepeated | LoopsDependency | Parallelizable |
| 1 | 1 | 0 | 1 |
| 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 1 |
This is a (totally inaccurate and random) dataset that has 4 variables (columns). IndependetParts reflects whether the program has some blocs that are independent from each other. LinesRepeated means that there are some parts that it has to compute/do many times (a for loop on the same line for example). LoopsDependency tells us if the segments that are encapsulated in a loop depend on the result calculated in a previous iteration or not. Finally, Parallelizable states if we can parallelize our code or not.
1 always means yes. 0 means no.
Each lines represents one program. It means that we have 8 different programs here.
If we want to predict the fourth one (Parallelizable), our decision tree will have to consider each feature (column) and see which one helps us more to distinguish if a code can be parallelised or not. Then we select it and split the codes according to that variable.
Easy, right? But it’s not done yet!
If we stop here, we could have something that can help us, but this will never be accurate because you wouldn’t know (and neither your algorithm) what to do in this case, if you choose the LoopsDependency, for example:
| IndependentParts | LinesRepeated | LoopsDependency | Parallelizable |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
Do you know how it can predict if it’s parallelizable or not? Because I don’t…
And this is why we have to consider all the variables that can help us (but not ALL the variables each time, some of them could be useless) reduce this uncertainty, or the errors that can occur.
BAM! You have a tree now! (Because you are splitting every time the “Branches” -will call them nodes-. The first one will be the root and the last ones that have no “children” will be called the leaves.
By the way, if I want to predict a quantitative variable, like in the table above, our decision tree will be called regression tree. If it predicts a categorical (qualitative) variable, it is called a classification tree! See below.
| FavoriteColor | LovesHPC | ReadsMyPosts | Cool |
| Red | 7 | 1 | 8.2 |
| Blue | 3 | 1 | 7.8 |
| Red | 5 | 0 | 3.1 |
| Yellow | 6 | 0 | 6 |
| Razzmatazz | 10 | 1 | 10 |
This is a (very serious?) dataset considering people’s favorite color, their love/interest in HPC and whether they read my blog posts or not to evaluate how cool they are. (Since you are reading this post, I give you 10!)
For the record, Razzmatazz is a real color. 89% red, 14.5% green and 42% blue. I can only imagine cool people knowing this kind of color names, I had to give a 10 here!
So since we are predicting this continuous variable (Cool), it is a regression tree! But don’t worry, if you are not used to this, you can still read the sections below since we won’t solicit this. But basically, you can see here what we are doing (only with one one stopping condition, there are others and this is simplifying -on purpose- a lot the code!):
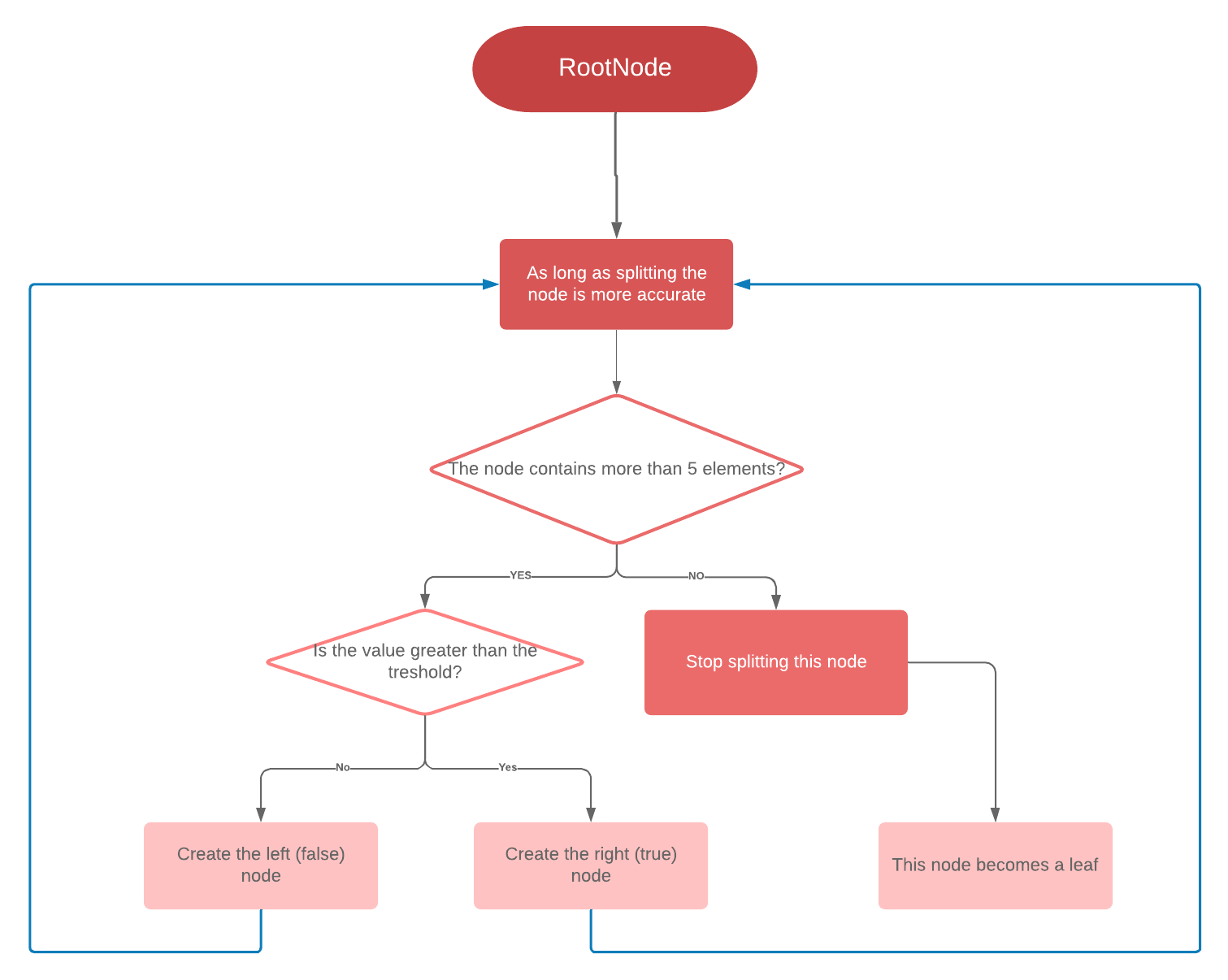
Note: If you are really into Machine Learning and would like to know more about the algorithms, check out the tutorials of this great teacher. Now if you want to know more about my C implementation, I would be very happy to talk about it with you and write a detailed post about it! Just contact me!
More Machine Learning
With this in mind, we can now go further and see what is a Gradient boosting decision tree.
So, to make it easy-peasy, just consider it as a repetition of what we were doing before (building trees) for a fixed number of times (usually 100). But this is done in a serial (dependent) way from the others. It means that, in order to build the tree No. i we have to consider the result (especially the errors) of the (i-1)th tree.
This is very useful to have more accurate predictions.
HPC
I know, I just said that gradient boosting implies a serial repetition of decision trees and that each step depends on the previous one, so parallelising is complicated here… but we actually won’t parallelise this part! What we will parallelise are those loops and independent parts of the decision trees!
There are lots of ways to parallelise the decision tree building part.
Since the algorithm finds the best value that can split the observations with a minimum error rate (the threshold in the algorithm you saw above), we could parallelise this part!
Another option would be the parallelisation of the node building parts. This would give something like this:
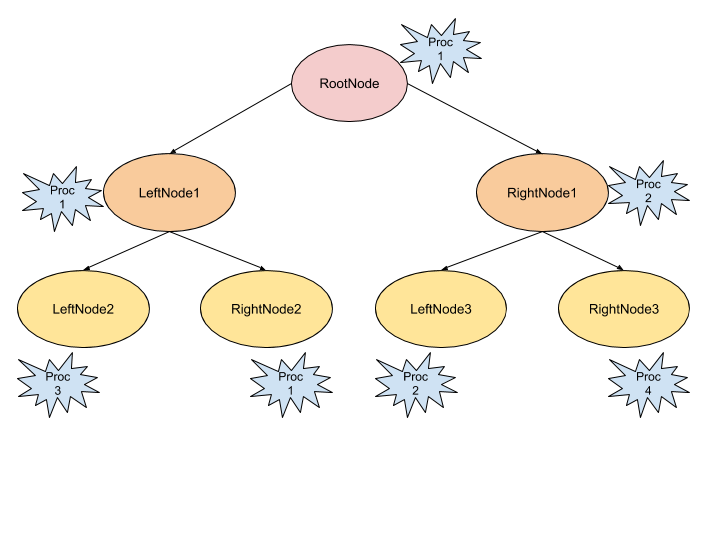
So the next step is to compare these different parallel versions and see if we can mix some to get better results!
I’m now very excited to see how all of this goes and which version will be better!
More HPC
Haha! You thought it was done! Well, no. But this part is not about the project, but still about HPC! (Not only)
Few weeks ago, we visited a museum that is located here in the Slovak Academy of Science, few meters away from the Computing Center. And guess what? It’s all about computers! I had such a gooood time there! The guide was so passionate about what he was talking about, and we saw some great things there. I’ll show you two things. You have to come here to see the others!



And now I’ll just say goodbye! I’ll do my best to post soon another post. As usual, if you have any suggestion or question, just send me a message on LinkedIn (on my bio).
Hi! My name is Thizirie, I am 24 years old and I'm currently studying Computer Science and Applied Mathematics in Paris. I love reading, listening to Rock'n'Roll, watching tennis games... and of course HPC and AI! Contact me here if you have questions or need some information before applying for SoHPC : Thizirie Ould Amer

Leave a Reply