Episode 2: The fellowship of performance

Ahoj! [pronounced: Ahoy]
Here is the essence of HPC: if someone tells you “congratulations you solved the problem”, that person is not HPC. All solutions should be met with “Congrats, now how do you solve a problem twice as big, or use a 2x computer to solve in half the time?”
Someone told me this in my last post’s comments, and it is definitely something I believe in. Thank you Rich for the advice.
Now, welcome to this second part of the HPC journey!
If you read my first article you already know how amazing my first week was in Bologna, Italy. (If you haven’t read it yet go check it out just here so you can know more about me and how this summer school started.)
Now let’s move to the core of this post!
Two weeks ago, I flew to Vienna then took the bus till Bratislava where I started my very exciting project which is about… High Performance Machine Learning! So I will be working every day here in the Computing Center of the Slovak Academy of Science on it!

Ciao Bologna! 
Ahoj Bratislava!
Machine Learning
Let’s start briefly with Machine Learning; one of those abstract fields we hear about, but do not really know what it is. Some people can take a quick look into the subject and have an insight about how cool it is, others chose to dive into this thrilling field in order to figure out how it works and learn to use it efficiently. The third kind of person includes the ones who let down their researches about ML because of maths, the huge amount of information. But let me tell you something; these people have more in common than what you think! First, they (we) all still have a lot of things to learn (there is no edge to improvements and knowledge) but also… they are all looking for efficiency.
So what is Machine Learning? (a brief introduction)
- A subset of artificial intelligence.
- It is about studying algorithms Based on statistics;
- Needs lots of data!
- Its goal is to derive meaning from the data you provide, but without giving explicit instructions (about correlations between some variables, for example)

Now, this is where magic happens! And by magic, I mean HPC…
Requiring huge amounts of data means that Machine Learning needs lots of resources for the processing and analysis of these inputs, and you may already be able to see what I am trying to point out… How critical time is for these problems of course!
The more data you have (to train your ML algorithm), the better it may perform (although, it depends on other parameters… We’ll see that later on other posts!) but this means that you need more time, more energy and more resources (computers or CPUs, cores, GPUs) to do everything.
So, with HPC we can reduce this runtime and make sure that our algorithms are able to run and process everything within an acceptable time. But you may ask me, how do we do that?
The answer is simple… Nah, just kidding. Otherwise there wouldn’t be a whole summer school dedicated to this matter and so many people working and trying to gain more in time/energy every day (by reducing the runtime, etc…).

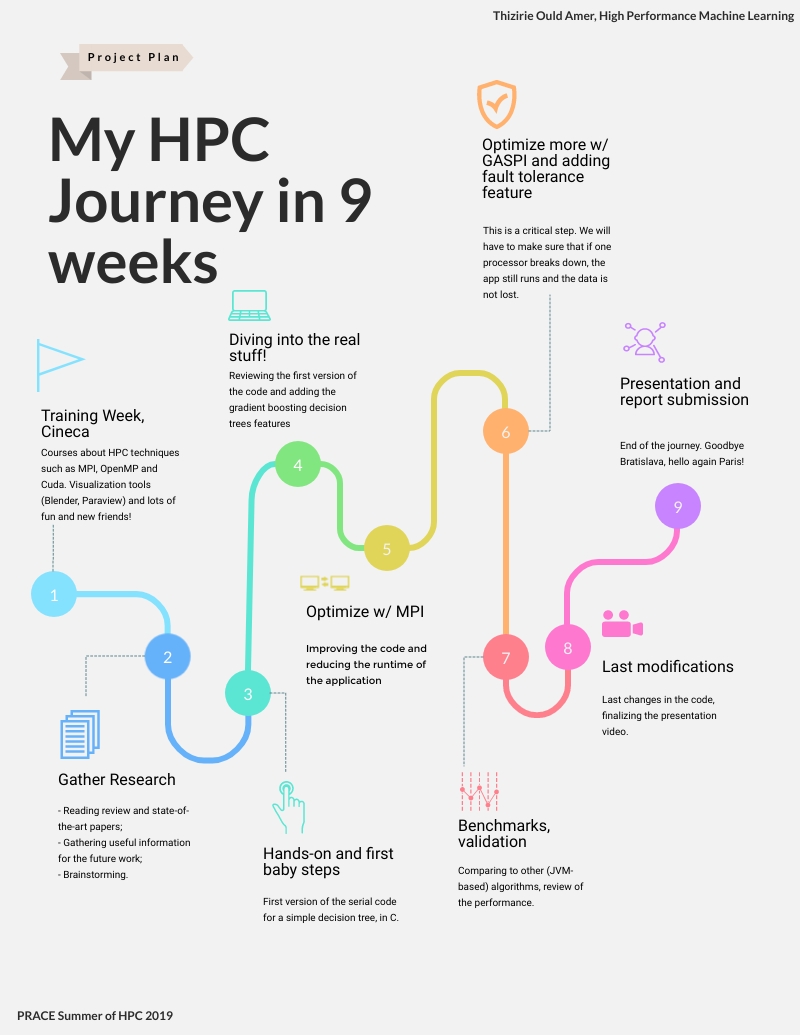
At this point you know what I will be dealing with this summer. There are only few points missing like the ML algorithm I am talking about. There are actually many of them. Nevertheless, I will only talk about Gradient boosting trees since I’ll work on this one.
In the future blog posts, we will delve into the aforementioned algorithm and how we are going to optimize it with MPI and GASPI (the HPC tools we were talking about). But don’t worry, we will talk about HPC before that and I will try to explain the concepts!
Now, I will leave you with my work plan and I look forward to hearing your feedbacks. See you next week for a less technical post where we will talk about trips, museums and food!
Hi! My name is Thizirie, I am 24 years old and I'm currently studying Computer Science and Applied Mathematics in Paris. I love reading, listening to Rock'n'Roll, watching tennis games... and of course HPC and AI! Contact me here if you have questions or need some information before applying for SoHPC : Thizirie Ould Amer
