Having the right toolkit at hand is crucial!

Hi everyone!
In my last blog post I introduced the Intel Movidius Neural Compute stick and sketched out a rough idea of what it is good for. In this post, I would like to build up on that and describe another very important component that accompanies the Neural Compute Stick, which is the OpenVino toolkit.
To make use of the Neural Compute Stick, it is necessary to first install the Open Visual Inferencing and Neural Network Optimization (OpenVino) toolkit, which I briefly introduced in my last post. This toolkit aims at speeding up the deployment of neural networks for visual applications across different platforms, using a uniform API.
I also touched in my last blog post on the difference between training a Neural Network and deploying it. To recap on that, training a Deep Neural Network is like taking a “black box” with a lot of switches and then tuning those for as long as it takes for this “black box” to produce acceptable answers. During this process, such a network is fed with millions of data points. Using these data points, the switches of a network are adjusted systematically so that it gets as close as possible to the answers we expected. Now this process is computationally very expensive, as data has to be passed through the network millions of times. For such tasks GPUs perform very well and are the de facto standard if it comes to hardware being used to train large neural networks, especially for tasks such as computer vision. If it comes to the frameworks used to train Deep Neural Networks, so there are a lot that can be utilized like Tensorflow, PyTorch, MxNet or Caffe. All of these frameworks yield a trained network in their own inherent file format.
After the training phase is completed, a network is ready to be used on yet unseen data to provide answers for the task it was trained for. Using a network to provide answers in a production environment is referred to as inference. Now in its simplest form, an application will just feed a network with data and wait for it to output the results. However, while doing so there are many steps that can be optimized, which is what so called inference engines do.
Now where does the OpenVino toolkit fit in concerning both tasks of training and deploying a model? The issue is that using algorithms like Deep Learning is not only computationally expensive during the training phase, but also upon deployment of a trained model in a production environment. Eventually, the hardware on which an application utilizing Deep Learning is running on is of crucial importance. Neural Networks, especially those used for visual applications, are usually trained on GPUs. However, using a GPU for inference in the field is very expensive and doesn’t pay off when using it in combination with an inexpensive edge device. It is definitely not a viable option to use a GPU that might cost a few hundred dollars to make a surveillance camera or a drone. If it comes to using Deep Neural Networks in the field, most of them are actually running on CPUs. Now there are a lot of platforms out there using different CPU architectures, which of course adds on to the complexity of the task to develop an application that runs on a variety of these platforms. That’s where OpenVino comes into play, it solves the problem of providing a unified framework for development which abstracts away all of this complexity. All in all, OpenVino enables applications utilizing Neural Networks to run inference on a heterogeneous set of processor architectures. The OpenVino toolkit can be broken down into two major components, the “Model Optimizer” and the “Inference Engine”. The former takes care of the transformation step to produce an optimized Intermediate Representation of a model, which is hardware agnostic and usable by the Inference Engine. This implies that the transformation step is independent of the future hardware that the model has to run on, but solely depends on the model to be transformed. Many pre-trained models contain layers that are important for the training process, such as dropout layers. These layers are useless during inference and might increase the inference time. In most cases, these layers can be automatically removed from the resulting Intermediate Representation.
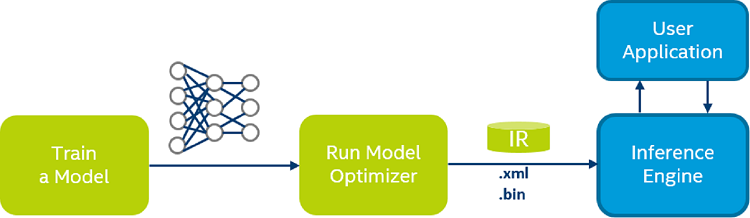
Even more so, if a group of layers can be represented as one mathematical operation, and thus as a single layer, the Model Optimizer recognizes such patterns and replaces these layers with just one. The result is an Intermediate Representation that has fewer layers than the original model, which decreases the inference time. This Intermediate Representation comes in the form of an XML file containing the model architecture and a binary file containing the model’s weights and biases.
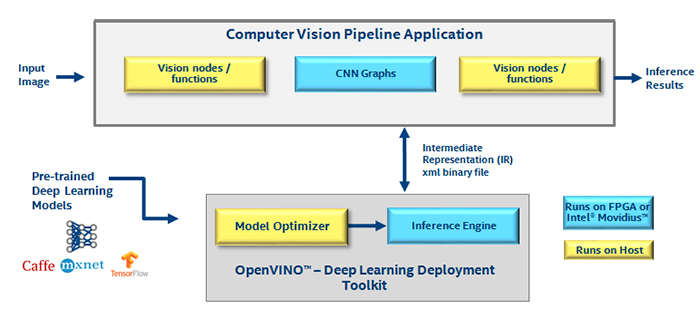
As shown in the picture above, we can split the locality of an application and the steps that utilize OpenVino into two parts. One part is running on a host machine, which can be an edge device or any other device “hosting” an accelerator such as the Neural Compute Stick. Another part is running on the accelerator itself.
After using the Model Optimizer to create an Intermediate Representation, the next step is to use this representation in combination with the Inference Engine to produce results. Now this Inference Engine is broadly speaking a set of utilities that allow to run Deep Neural Networks on different processor architectures. This way a developer is capable to deploy an application on a whole host of different platforms, while using a uniform API. This is made possible by so called “plugins”. These are software components that contain complete implementations for the inference engine to be used on a particular Intel device, be it a CPU, FPGA or a VPU as in the case of the Neural Compute Stick. Eventually, these plugins take care of translating calls to the uniform API of OpenVino, which are platform independent, into hardware specific instructions. This API encompasses capabilities to read in the network’s intermediate representation, manipulate network information and most importantly pass inputs to the network once it is loaded onto the target device and get outputs back again. Now a common workflow to use the inference engine includes the following steps:
- Read the Intermediate Representation – Read an Intermediate Representation file into an application which represents the network in the host memory. This host can be a Raspberry Pi or any other edge or computing device running an application utilizing the inference engine from OpenVino.
- Prepare input and output format – After loading the network, specify input and output dimensions and the layout of the network.
- Create Inference Engine Core object – This object allows an application to work with different devices and manages the plugins needed to communicate with the target device.
- Compile and Load Network to device – In this step a network is compiled and loaded to the target device.
- Set input data – With the network loaded on to the device, it is now ready to run inference. Now the application running on the host can send an “infer request” to the network in which it signals the memory locations for the inputs and outputs.
- Execute – With the input and output memory locations now defined, there are two execution modes to choose from:
- Synchronously to block until an inference request is completed.
- Asynchronously to check the status of the inference request while continuing with other computations.
- Get the output – After the inference is completed, get the output from the target device memory.
After laying the foundations for working with the Intel Movidius Neural Compute Stick and the OpenVino toolkit in this and my last blog post, I will elaborate on what the “dynamic” in my project title stands for. So stay tuned for more!
