Automated Extraction of Metadata from Climate Simulations: Project Wrap-Up

1. Introduction
As the project intensively included the processing of NetCDF datasets, this section serves as a brief background to the NetCDF format and its underlying data structure. NetCDF stands for “Network Common Data Form”. The NetCDF creators (Rew, Davis, 1990) defined it as a set of software libraries and self-describing, machine-independent data formats that support the creation, access, and sharing of array-oriented scientific data. It actually emerged as an extension to the NASA’s Common Data Format (CDF). NetCDF was developed and is maintained within the Unidata organisation.
The NetCDF data abstraction, models a scientific dataset as a collection of named multi-dimensional variables along with their coordinate systems, and some of their named auxiliary attributes. Typically, each NetCDF file has three components including: i) Dimensions, ii) Variables, and iii) Attributes. On one hand, dimensions describe the axes of the data arrays. A dimension has a name and a length. On the other hand, a typical NetCDF variable has a name, a data type, and a shape described by a list of dimensions. Variables in NetCDF files can be one of six types (char, byte, short, int, float, double). Scalar variables have an empty list of dimensions. Any NetCDF variable may also have an associated list of attributes to represent information about the variable.
Figure 1 illustrates The NetCDF abstraction with an example of dimensions/variables that can be contained in a NetCDF file. The variables in the example represent a 2D array of surface temperatures on a latitude/longitude grid, and a 3D array of relative humidities defined on the same grid, but with a dimension representing atmospheric level.
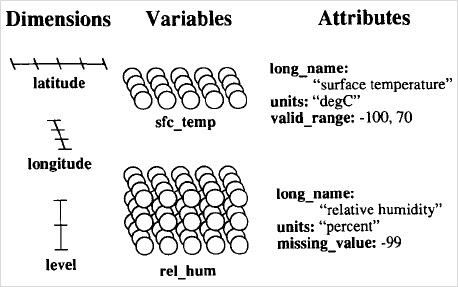
Figure 1: NetCDF data structure.
2. Problem Description
Climate researchers and institutions can share their NetCDF datasets on the DSpace data repository. However, a shared file can be considered as a “black box”, which always needs to be opened first in order to know what is inside. In fact, climate simulation models generate vast amounts of data, stored in the standard NetCDf format. A typical NetCDF file can contain a set of many dimensions and variables. With so many files, researchers can spend a lot of time trying to find the appropriate file (if any). Figure 2 portrays the problem of sharing NetCDF datasets on DSpace.
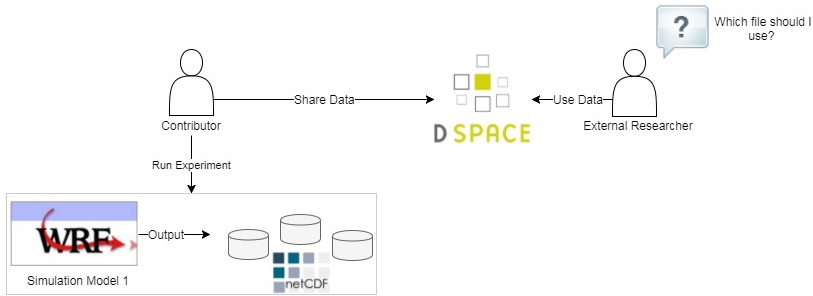
Figure 2: Problem description.
3. Project Objectives
The main goal of the project was to produce explanatory metadata that can effectively describe NetCDF datasets. The metadata should also be stored and indexed in a query-able format, so that search and query tasks can be conducted efficiently. In this manner, we can facilitate the search and query of NetCDF datasets uploaded to the DSpace repository, so that researchers can easily discover and use climate data. Specifically, a set of objectives were defined as below:
- Defining the relevant metadata structure to be extracted from NetCDF files.
- Extraction of metadata from the NetCDF files.
- Storage/indexing of extracted metadata.
- Extending search/querying functionalities.
The project was developed in a collaboration between GrNet and the Aristotle University of Thessaloniki. GrNet provided us with access to the ARIS supercomputing facility in Greece, and they also manage the DSapce repository. The ARIS supercomputer is usually utilised to run the computationally intensive climate simulation models. The output of simulation models was also stored on ARIS.
4. Data Source
As already mentioned, the DSpace repository contained the main data source of NetCDF files. DSpace is a digital service that collects, preserves, and distributes digital material. Our particular focus is on climate datasets provided by Dr Eleni Katragkou from the Department of Meteorology and Climatology, Aristotle University of Thessaloniki. The datasets are available through the URL below:
https://goo.gl/3pkW9n
5. Methodology
The project was mainly developed using Python. A set of packages was utilised as follows: i) NetCDF4., ii) xml.etree.cElementTree., iii) xml.dom.minidom., iv) glob, and v) os.
Subsequently, the extracted metadata was encoded using the standard Dublin Core XML-based schema. The Dublin Core Schema is a small set of domain-independent vocabulary terms that can be used to describe information or data in a general sense. The full set of Dublin Core metadata terms can be found on the Dublin Core Metadata Initiative (DCMI) website. Figure 3 sketches the stages of project development. Furthermore, the full implemented Python code can accessed on GitHub via:
https://github.com/Mahmoud-Elbattah/Extract_Metadata_NetCDF
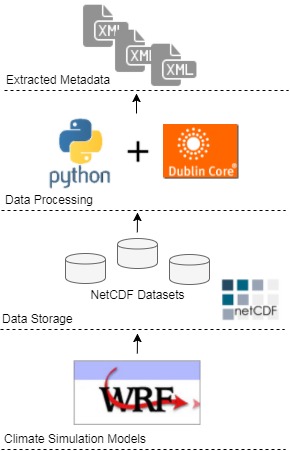
Figure 3: Project overview.
6. Extracted Metadata
The project outcomes included the following:
- More than 40K metadata fields were extracted.
- 940 DublinCore-based XML files.
Figure 4 provides an example of the extracted metadata.

Figure 4: Example of extracted metadata.
7. Project Mentors
 Dr Eleni Katragkou Department of Meteorology and Climatology, Aristotle University of Thessaloniki |
 Dr Ioannis Liabotis Greek Research and Technology Network, Athens, Greece |
8. Acknowledgements
First, I would like to thank my mentors Ioannis Liabotis and Eleni Katragkou for their kind support and help. Further, many thanks to Dimitris Dellis from GrNet who provided a lot of technical support during the project development. Last but not least, thanks to Edwige Pezzulli for her kind collegiality and companionship.
References
McCormick, B. H. (1987). Visualization in Scientific Computing. Computer graphics, 21(6), 1-14
Check out my video presentation about the project:

Leave a Reply