Data is everywhere around us
Hello again, this time from my hometown of Kavadarci, and welcome to my second blog post about my remote, summer internship at the CINECA research center in Bologna. As I have already described in my previous post, this summer I am working on a project to detect anomalies in the work of the Marconi100 cluster at CINECA.
My job in this project is to gather the data set on the Marconi100 cluster that contains information about nearly every environmental factor that impacts it’s working performance and store in Delta Lake format.
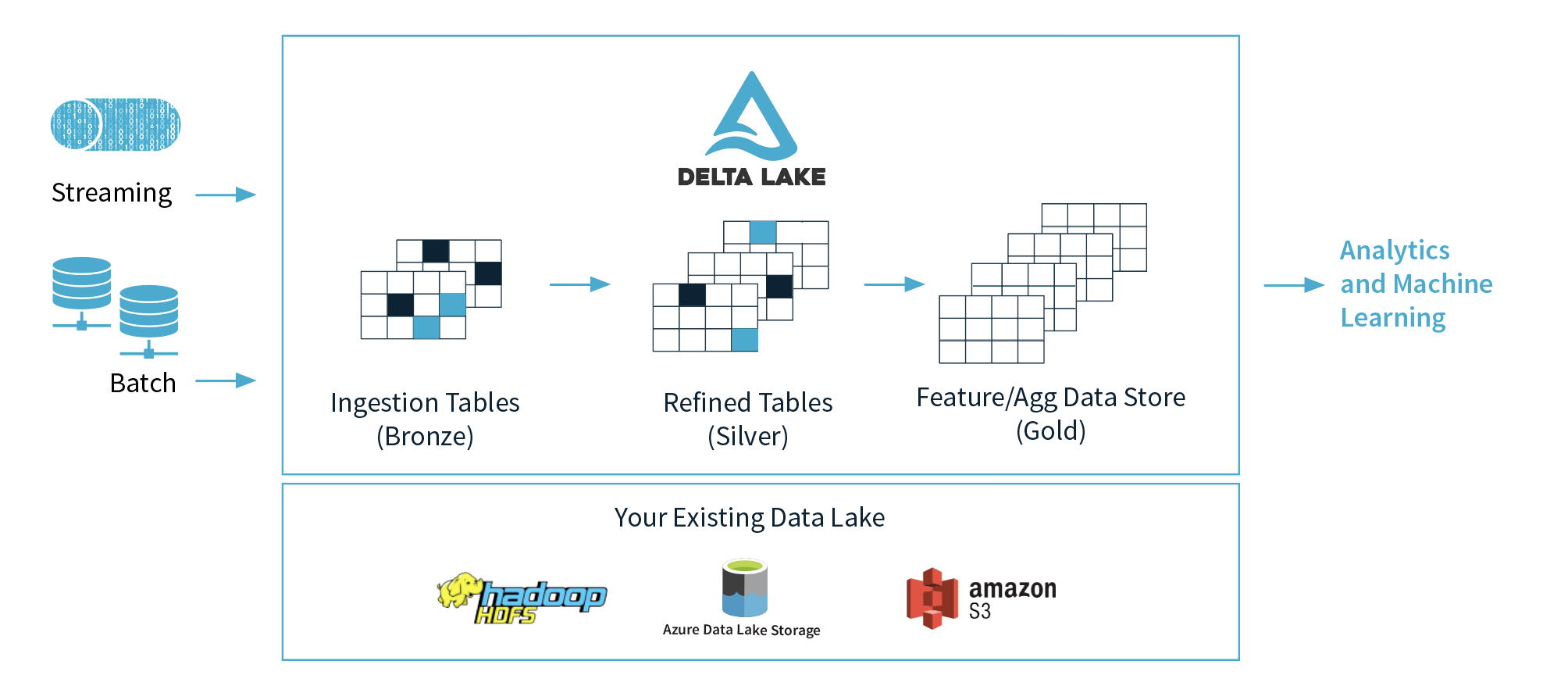
Delta Lake is an open-source storage layer within the Apache Spark engine that offers ACID (atomic, consistent, isolated, durable) transactions to its big data workloads. A major feature of Delta Lake is to enforce the schema of the data set during writing; something that has been missing so far from Spark. Another really important feature is that Delta Lake works seamlessly with Apache Parquet; that is – it stores the data in column-oriented format which is substantially faster than the more-common, traditional row-oriented format.
Consider for example a question that might arise from this data: Plot the temperature of node X for May through August 2020 and check if there are any anomalies (unusually high or low values) in it? In the traditional row-oriented format, the processing engine would have to read a batch of rows, and for each row it should scan up to it’s N-th column (where the temperature is stored) and this could take a while, considering that there might have been many columns in between that can be large in memory and force the engine to read more disk blocks.
Now with the column-oriented format, each temperature value is stored right next to each other and reading the column data can be very fast (fewer disk reads). Also, we would need less storage for the data, because there are techniques for compressing it (each column contains homogeneous data). In big data scenarios, column-oriented storage is the way to go.
As the project is coming to an end, I am hoping that there will be enough time to use this data to train a machine learning model to automatically detect anomalies. Stay tuned to read about it in my next blog post.
Stay safe.
