Episode 4: Epilogue.

Hello dear readers! Today, we will write the ending of this story.
A story that lasted for two months. TWO MONTHS. For me, July was full of surprises and new friends, August was full of wonders and adventures!
But let’s start by a summary of my project:
Last time I talked about Gradient Boosted Decision Trees (GBDT) and addressed quickly the parallelization methods. This time we will dig deeper into this aspect! So how can we parallelize this program?
Well, when it comes to the concept of a parallel version of a program, many aspects have to be taken into account, such as the dependency between various parts of the code, balancing the work load on the workers, etc.
This means that we cannot parallelize the gradient boosted algorithm’s loop directly since each iteration requires the result obtained in the previous one. However, it is possible to create a parallel version of the decision trees building code.
The algorithm for building Decision Trees can be parallelized in many ways. Each of the approaches can potentially be the most efficient one depending on the size of data, number of features, number of parallel workers, data distribution, etc. Let us discuss three viable ways of parallelizing the algorithm, and explain their advantages and drawbacks.
1. Sharing the tree nodes creation among the parallel processes at each level
The way we implemented the decision tree allows us to split the effort among the parallel tasks. This means that we would end up with task distribution schematically depicted in the figure below:
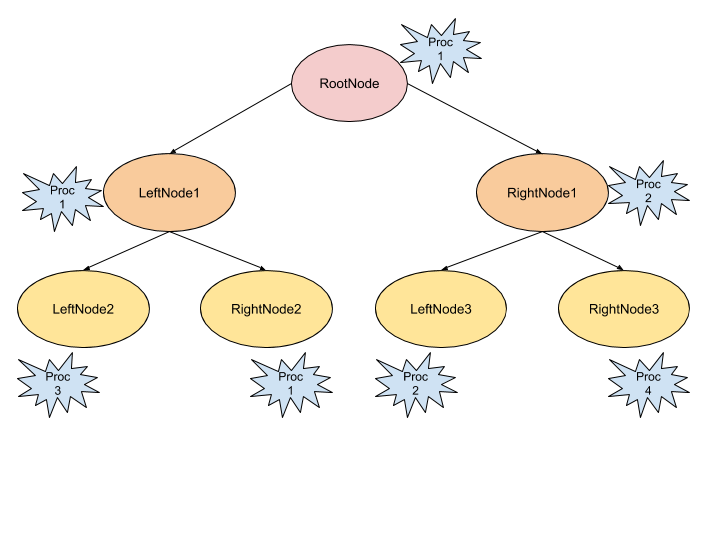
Yet, we have a problem with this approach. We can imagine a case where we would have 50 “individuals” going to the left node, and 380 going to the right one. We will then expect that one processor will process the data of 50 individuals and the other one will process the data of 380. This is not a balanced distribution of the work, some processors doing nothing while others maybe drowning in work. Furthermore, the number of tree nodes that can be processed in parallel limits the maximum number of utilizable parallel processes… So we thought about another way.
Sharing the best split research in each node.
In our implementation of the decision tree algorithm, there is a function that finds the value that splits the data into groups with minimum impurity. It iterates (for a fixed column — variable) through all the different values and calculates the impurity for the split. The output is the value that reaches the minimum impurity.

As can be seen in the figure above, this is the part of the code that can be parallelized. So every time a node has to find a split of individuals in (two) groups, many processors will compute the best local splitting value, and we keep the minimum value from the parallel tasks. Then, the same calculations are repeated for the Right data on one side, and for the Left Data on the other.
In this case, a parallel process will do its job for a node and when done it can directly move to another task on another node. So, we got rid of the unbalanced workload since (almost) all processes will constantly be given tasks to do.
Nevertheless, this also has an notable drawback. The cost in communication is not always worth the effort. Imagine the last tree level where we would have only a few individuals in each node. The cost of the communication in both ways (the data has to be given to each process, and received the output at the end). The communication will eventually slow down the global execution more than the parallelization of the workload speeds it up.
Parallelize the best split research on each level by features
The existing literature (See) helped us to merge some features of the two aforementioned approaches to find one that reduces or eliminates their drawbacks. This time, the idea is to parallelize the function that finds the best split, but for each tree level. Each parallel process calculates the impurity for a particular variable across all nodes within the level of the tree.
This method is expected to work better because:
- The workload is now balanced because each parallel process evaluates the same amount of data for “its feature”. As long as the number of features is the same (or greater, ideally much larger) than the number of parallel tasks, none of the processes will idle.
- The impact of the problem we described in the second concept is reduced, since we are working on the whole levels rather than on a single node. Each parallel task is loaded with much larger (and equal) amounts of data, thus the communication overhead is less significant.
The global concept is shown in this figure:

And now let’s see one way to improve all of this. We will focus on the communication, particularly its timing.
While we cannot completely avoid loosing some wall-clock time in sending and receiving data, i.e. communication among the parallel processes, we can rearrange the algorithm (and use proper libraries) to facilitate overlap of the computation and communication. As shown in the the figures below, in the first case (a) we notice that the processor waits until the communication is done to launch the calculations, whereas in the second case (b) it starts computation before the end of the communication process. The last case (c) shows different ways to facilitate total computation-communication overlap.


One of the libraries that allows for asynchronous communications patterns, thus overlap of computation and communications is the GPI-2, an open source reference implementation of the GASPI (Global Address Space Programming Interface) standard, providing an API for C and C++. It provides non-blocking one-sided and collective operations with strong focuses on fault tolerance. Successful implementations is parallel matrix multiplication, K-means and TeraSort algorithms are discribed in Pitonak et al. (2019) “Optimization of Computationally and I/O Intense Patterns in Electronic Structure and Machine Learning Algorithms.“
So we’re done now!
We have discussed some of the miscellaneous possible parallel versions of this algorithm and their efficiency. Unfortunately we did not have enough time to finalize the implementations and compare them with the JVM-based technologies but also with XGBoost performances.
Future works could focus on improving and continuing the implementations and comparing them to the usual tools. Including OpenMP in the parallelization could also be a very interesting approach and lead to a better performance.
Another side that could be considered as well is using the fault tolerant functions of GPI-2 which would ensure a better reliability for the application.
Now what?
Now I am going back to Paris for a few days. Full of energy, full of knowledge and with a great will to come back here.
This summer has been crazy. In two months I met some incredible people here and I am sooo grateful for all of this.
The first week in Bologna was a great introduction to the HPC world. We learned a lot and got the chance to meet and know more about each other. I really hope we will keep in touch in the future! I’d love to hear about what everyone will be working on, etc.

Then Irèn and I got the incredible chance to work with the CC SAS team here in Bratislava. People are so nice and the city is lovely! I’d like to take this opportunity to thank my mentors and the whole team for their help and kindness (and the trips!).





Living in Bratislava does not only mean living in a lovely city. It also means being in the middle of many other countries and big cities. So I was able to visit Vienna with Irèn (and we actually met 3 SoHPC participants who came from Ostrava and Ljubljana, we spent a great weekend together!), then I visited Prague (And fell in love with it) and Budapest!

From left to right: Pablo (Ostrava), me, Khyati (Ljubljana), Irèn (Bratislava), and Arsenios (Ljubljana).
Well, well, well. I think that’s all what I have to say. You should apply and come to discover by yourself! I can promise that you won’t regret it.
Check my LinkedIn if you want some more information and drop me a message there!
Hi! My name is Thizirie, I am 24 years old and I'm currently studying Computer Science and Applied Mathematics in Paris. I love reading, listening to Rock'n'Roll, watching tennis games... and of course HPC and AI! Contact me here if you have questions or need some information before applying for SoHPC : Thizirie Ould Amer

Leave a Reply