MEEP MEEP!

Hello !
Welcome to my blog post #2 where we get deep into the MEEP! If you have not yet read #1 you can do so here . In this post , I will give more comprehensive outlook to the project and talk about my progress as well.
The Memory Hierarchy
Before delving into the nitty – gritties of the project, it is important to understand what the memory hierarchy is and why it is a fundamental factor that determines the performance of any computing system.
Imagine there’s a large store in your city (This is obviously before the times of online shopping). İt is well stocked and has got everything you can think of , from a lawnmower to kitchen napkins. But there’s a catch. Shopping in this store takes quite some time because :
- Since it has so much stuff, you have to go through so many aisles to get to what you need.
- The store is located further away from your home .
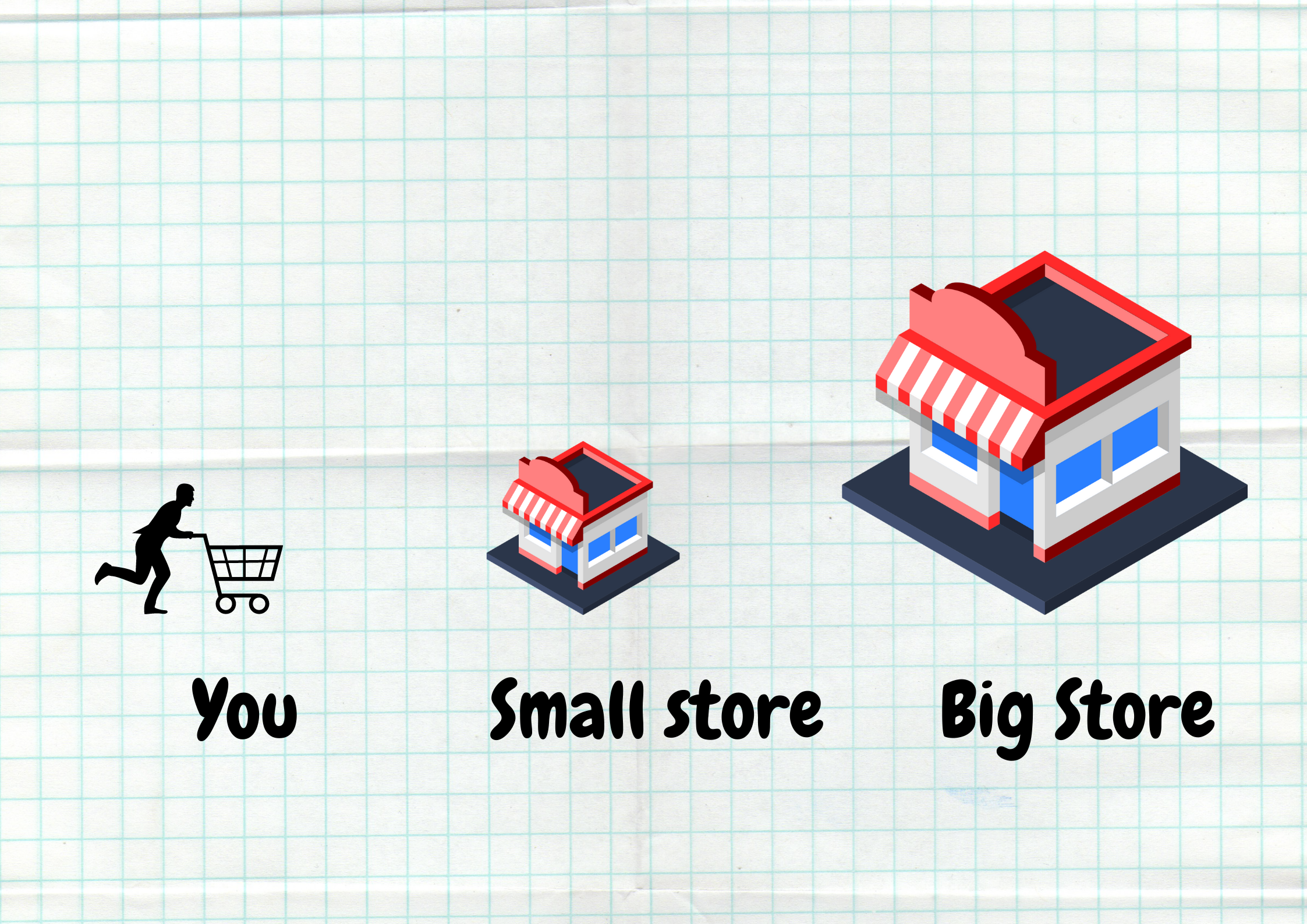
Time is money, so your city’s municipality decides to build a smaller supermarket near your neighborhood. It is not as equipped as the mega store , but it has most of the stuff that you need frequently. Furthermore, if you ever needed anything that is only in the larger store , it could be fetched and brought to the small supermarket. Pretty cool, right?
This is basically how the memory hierarchy operates. We have smaller, faster memory levels placed closer to the CPU (Central Processing Unit) and they contain only the data and code we need at the moment, hence faster speed in processing.
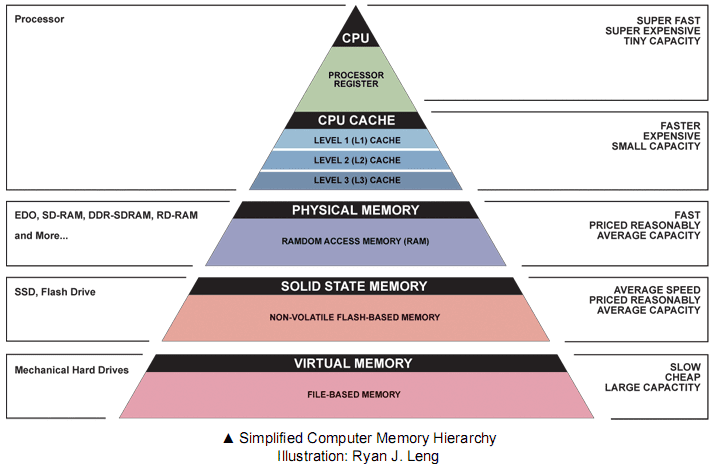
Need for Speed
This project proposes various placement and management policies that optimize the movement of data and instructions through the memory hierarchy. These novel policies would have to be tested and experimented upon before casting them onto silicon and MEEP offers an excellent platform to do this.
MEEP (MareNostrum Experimental Exascale Platform), is an FPGA (Field Programmable Gate Array) – based platform that enables us to evaluate new architectural ideas at speed and scale level and also enables software readiness for new hardware. It would be easier to think of MEEP as a foundational prototype that can be used to test the viability of a certain framework or architecture. One of the unique features of MEEP is a self-hosted accelerator. This means that data for the calculations can reside in the accelerator memory and does not have to be copied to/from the host CPU. This accelerator is part of the chiplet architecture called the ACME (Accelerated compute and Memory Engine). A key differentiator of ACME is that it employs a decoupled architecture in which the memory operations are separated from the computation. While dense HPC workloads are compute-bound in which the accelerator tiles represent the bottleneck, sparse workloads are memory-bound as the vector elements need to be gathered/scattered using multiple memory requests.
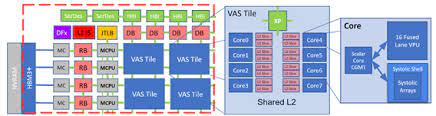

Coyote Simulator
The cherry-on-top to this accelerator of the future is the Coyote simulator that is responsible for its performance modelling and analysis. My role in this project is centered around this simulator, the MCPU simulation specifically. Coyote is founded on existing simulators (Spike and Sparta) and is being improved by catering for their shortcomings,especially in the HPC domain in which the number of resources to be simulated is high, hence making it a powerful modelling tool. The name “Coyote” was adapted from the Looney Tunes cartoon series “Wile E. Coyote and the Road Runner”.
These past two weeks, I was busy setting up the simulator repository and dependencies in my PC and working on scheduling policies of load and store instructions within the MCPU . The latter is still a work in progress and I plan to expound on it in my next blog post.
Emulation … Simulation … what’s the difference?
Simulation involves creating an environment that mimics the behavior of the actual environment and is usually, only software oriented. Emulation, on the other hand involves duplicating the actual environment both in the hardware and software spectrum. Below is an illustration of how the MEEP project implements both emulation and simulation.
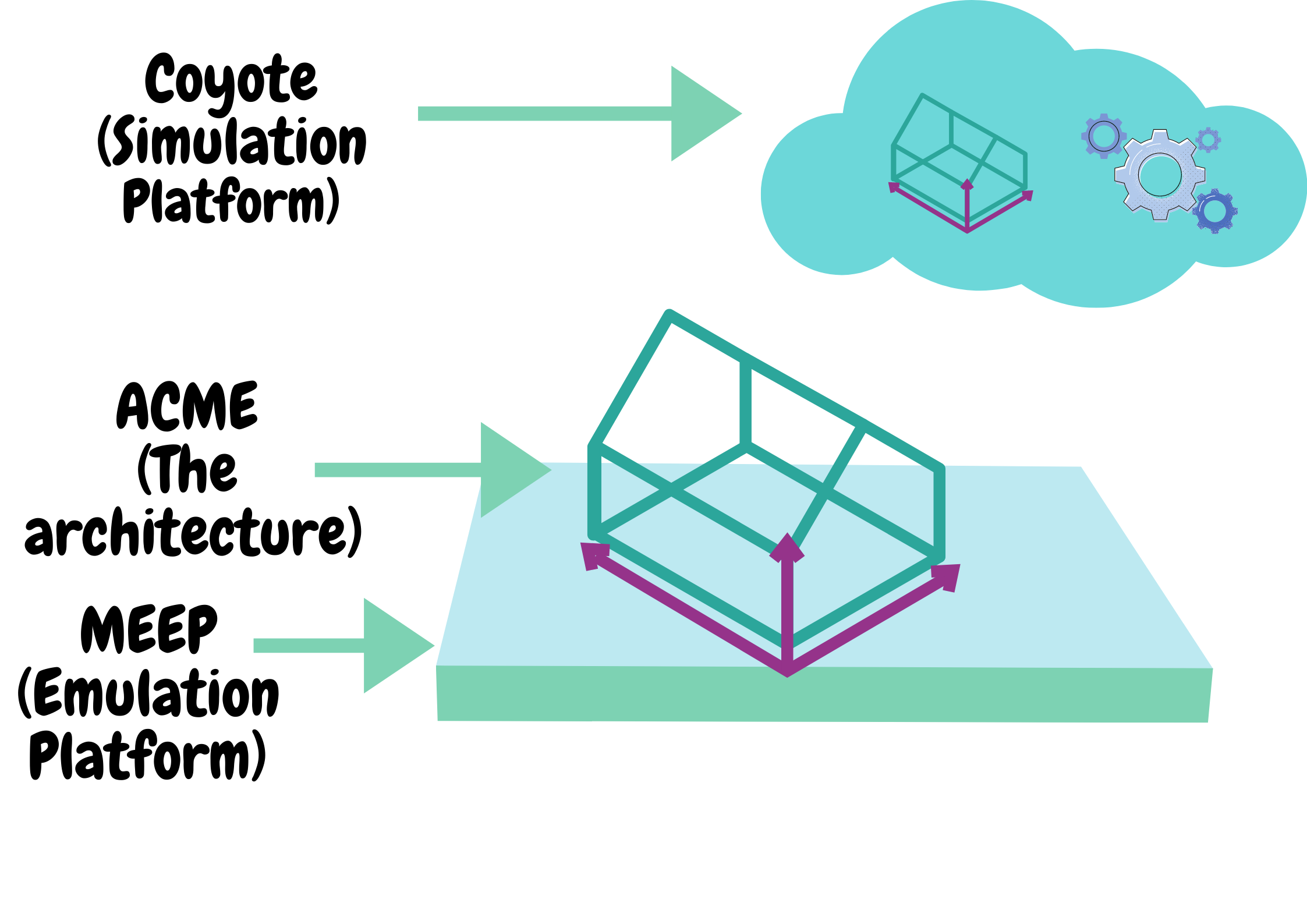
And that’s it for blog post #2. This was a long one so congrats if you made it this far. I hope you have learnt something new or gained a clearer perspective of our project. I’d be happy to answer any questions you may have about the project so feel free to comment below.
Blog post #3 coming soon!

I am learning more about computing here than I did in my five years in Campus😂
I hope I can ’emulate’ all these that you’re doing Reggie🙌🏽
Can’t wait for the third one🤗
Thank you for reading Moses 🙂
Same! You spoke my mind, so this is me hopping on this comment 😅.
Great Regina👏🏾
Thank you Esther! Glad to have you on board 🙂
Interesting and detailed read. The analogy goes a long way to help in understanding memory hierarchy. Oh! And now I know the difference between simulation and emulation. Looking forward to more blogs.
Keep going Mumbi!
Cheers!
Expand on the MCPU.
Thank you for reading Arodi. That will be the topic for my next blog. So stay tuned:)
This is very good and detailed content! Amazing work
Thank you Victor 🙂
What a recap of most of my Digital Electronics course. I am fascinated by microprocessors and this piece was great to dive into. I am proud to have a friend who is well versed in this area and I am really interested in your project.
Go on Mumbi!
Glad to have you here Lee!
Awesome piece Reggie !
Thank you Noah!
Nice work!
Asante George!
Excellent read. The breakdown at the beginning was fantastic.
Hope you learnt something new!
Good work Regina!
Thanks Polet!
Great work Regina
Thank You Diana 🙂
The catchy titles make this piece easier and more interesting to read.
Good job!
Glad you enjoyed it Moses 🙂