Near the end (or already there?)

I know I haven’t kept my promise of giving a regular heads-up on what is going on with my project, but these last days have been so extremely busy and overwhelming that haven’t allowed me to do so. Overwhelming, in the sense that a beautiful chapter has just finished, while a new, interesting one is ready to be written.
Here I am now, many feet over the earth surface on a flight back to Greece where I will complete my studies thinking how I should summarize a two-month-work in just a few words. So… let us start from where we left it the last time.
Diving in the details…
In order to monitor memory interactions we opted for Valgrind as it offers the additional possibility of simulating cache behaviour. That is, when we run our application under Valgrind, all data accesses can be monitored and collected giving the chance of determining all those accesses that missed cache and had to deploy memory subsystems deeper in the hierarchy. Considering every accessed data in isolation would be neither intuitive nor helpful for further post-processing. This is where EVOP intervenes in order to group data into memory objects. An object can be an array of integers, a struct or any other structure the semantics of which suggest that it has to be considered as an entity. Such objects, regardless if they are statically or dynamically allocated are labeled and every time an access is issued, it is tied to the related object.
Setting the aforementioned comparison of software and hardware approach as our ultimate scope, we enhanced EVOP with the option of performing sampled data collection. In detail, we extended Valgrind source code by integrating a global counter which increments on every memory access. While counter’s value is below a predetermined threshold no access shall be accounted for. On the contrary, the memory access that forces counter and threshold to be equal will be monitored and therefore accumulated to the final access number. The threshold is to be plainly defined when EVOP is called.
What is more, we familiarized with the internal Valgrind representation of memory accesses in order to distinguish between “load” and “store” ones. Similarly as before, we added a counter that increments every time a load or store is detected. The sole accesses that are to be monitored are the ones that equalize the counter to the predetermined threshold. This time, the user has to define a combination of flags in order to specify the type of accesses to be sampled as well as the respective sampling period.
Having enabled these two features our methodology can be summarized in the following procedure: We initially performed a simulation of our benchmarks without sampling in order to get the total number of memory objects. The latter were processed by a BSC-developed tool in order to be optimally distributed to the available memory subsystems. The distribution takes into consideration the last-level cache misses of each object as well as the number of loads that refer to each one of them and sets as its goal the minimization of the total CPU stall cycles. The total “saved” cycles are calculated along with the object distribution and thus the final speedup can be determined. This speedup is the maximum achievable given the application and the memory subsystem mosaic.
What follows is a trial-and-error experimentation process of obtaining results using various sampling periods to extract the referenced objects. It can be intuitively assumed that the longer the sampling period is, the fewer the total memory accesses will be, too. Given the fact that each access is related to one memory object, the fewer the accesses are, the less the possibilities are that not all existing memory objects are discovered. The latter presumably results in a worse distribution; worse in the sense that the final speedup is lower than the initial, achievable one. Nevertheless, depending on the access pattern of each benchmark, there is a specific sampling period, or a restricted range of neighboring sampling periods, that identify all the objects responsible for the initial speedup.
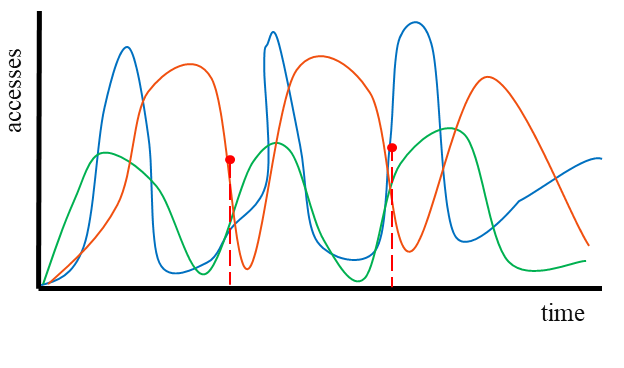

In the first two figures I present a qualitative representation of the memory access behavior for each application, as it was understood by me. Sparse sampling, in the first case, is not enough to account for every “important” object, while in the second case, due to the different access pattern, this is allowed. Regarding the exact correlation between the final speedup and the sampling period used to get the objects, in the first case, there is a strict threshold, after which the final results are strongly damaged, in the second case this threshold can be generalized in a larger neighborhood of periods.
Closure
Since this experience has reached its end, it wouldn’t be fair to pay the just tribute to the SoHPC program. Disregarding the undoubtedly deep learning outcome of the program, one can benefit from it expanding one’s personality and experiences. The fact that we are given the chance to live first-hand in a foreign country poses a challenge, yet presents an opportunity to discover and develop one’s self. All in all, SoHPC provides as an important alternative that enriches both technical skills and personal qualitites.
If you want to keep up with me please check my personal page at LinkedIn!
Hi there! I am Dimitris, a greek ex-student and future job-seeker who will be spending his summer in Barcelona. Although spanish beaches are among the best in the world, the reasons behind this experience are more professional than recreational - by the way, who said that these two cannot be combined? The kick off was a training week at CINECA, Bologna, while the sequel includes Barcelona Supercomputing Center in Spain where I will be collaborating with a big team in order to exploit heterogeneous memory systems using application profiling techniques. Hopefully my experience in High Performance Computing, Embedded Systems and Computer Architecture will give me an important advantage! Let's see...

Leave a Reply