Precision Based DCP Implementation

Hello everyone!
We have come to an end now and we all gained a lot for both hard and soft skills. We’ve done so many things and I will try to cover all together in this post.
At first, as I said in my last post, I want to tell about Precision Based Differential Checkpointing (PBDCP) technique which is the method I’ve implemented through the project.
PBDCP is implemented for float and double type data sets. Floating point numbers map decimal numbers to a unique bit representation and they have 3 parts: sign bit, mantissa and exponent. The idea of Precision Based Differential Checkpointing is to cap the last bits of mantissa that are the least significant bits according to the given precision value. As an example in Figure below , if the precision value given by user is sixteen, it truncates the last seven bits of mantissa, (i.e. makes them 0).

Therefore, PBDCP allows us to take benefits from dcp share which shows the difference between checkpoints, those would be stored, for such small changes.The advantage is transferring less data and preventing from creating continuous traffic for such minor changes.
Usage
To use this mechanism, there are some basic additions in the configuration file. Firstly, enable_pbdcp value should be set to 1 and pbdcp_precision value should be entered. Then, in the application when calling FTI_Checkpoint function, user should specify the level for pbdcp which is FTI_L4_PBDCP.
Experiment Results
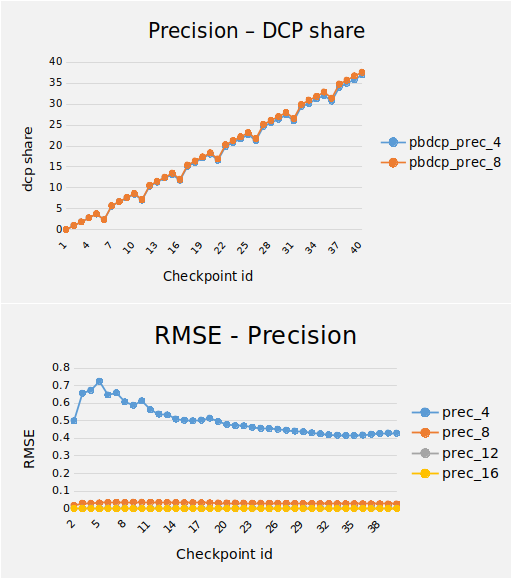
As expected, the smaller the precision the most benefit we can get from dcp share since the value remains unchanged for a certain interval but also the larger the rmse value which is route means square error for uncapped and capped values and it can also be seen in charts left Precision against DCP share and RMSE on top on the page in which: dcp blocksize=1024, Iteration= 200, Checkpoint interval= 5 (which means there are 40 checkpoints) values are used.
And for comparing pure dcp and precision based dcp, again as expected dcp share is lower in pbdcp and an example result of an execution with values as: Block size= 1024, Precision= 4, Iteration= 200, Ckpt Interval= 5 is shown in graph below.

So this is the work I studied on during this internship. My project mate Thanos and I prepared a video presentation for SoHPC which you can watch here…
Ending
I had a great two months. I was a bit nervous in the beginning but it lasted only till I met with mentors, coordinators, BSC group, other students so on and so forth. They are all such helpful, warmhearted and sincere that no need to hesitate at all. I am greatful to all for giving us the chance to be part of this awesome adventure together.
And that’s the end, best wishes to you all…

Leave a Reply