Radiation, invisible power around you
Hello everyone !
Life is fantastic in Ljubljana. Working in the surroundings of wonderful mountains makes me feel like a hero of a fairy tale. We’ve changed the month in the calendar but I still can’t believe how fast time passes.
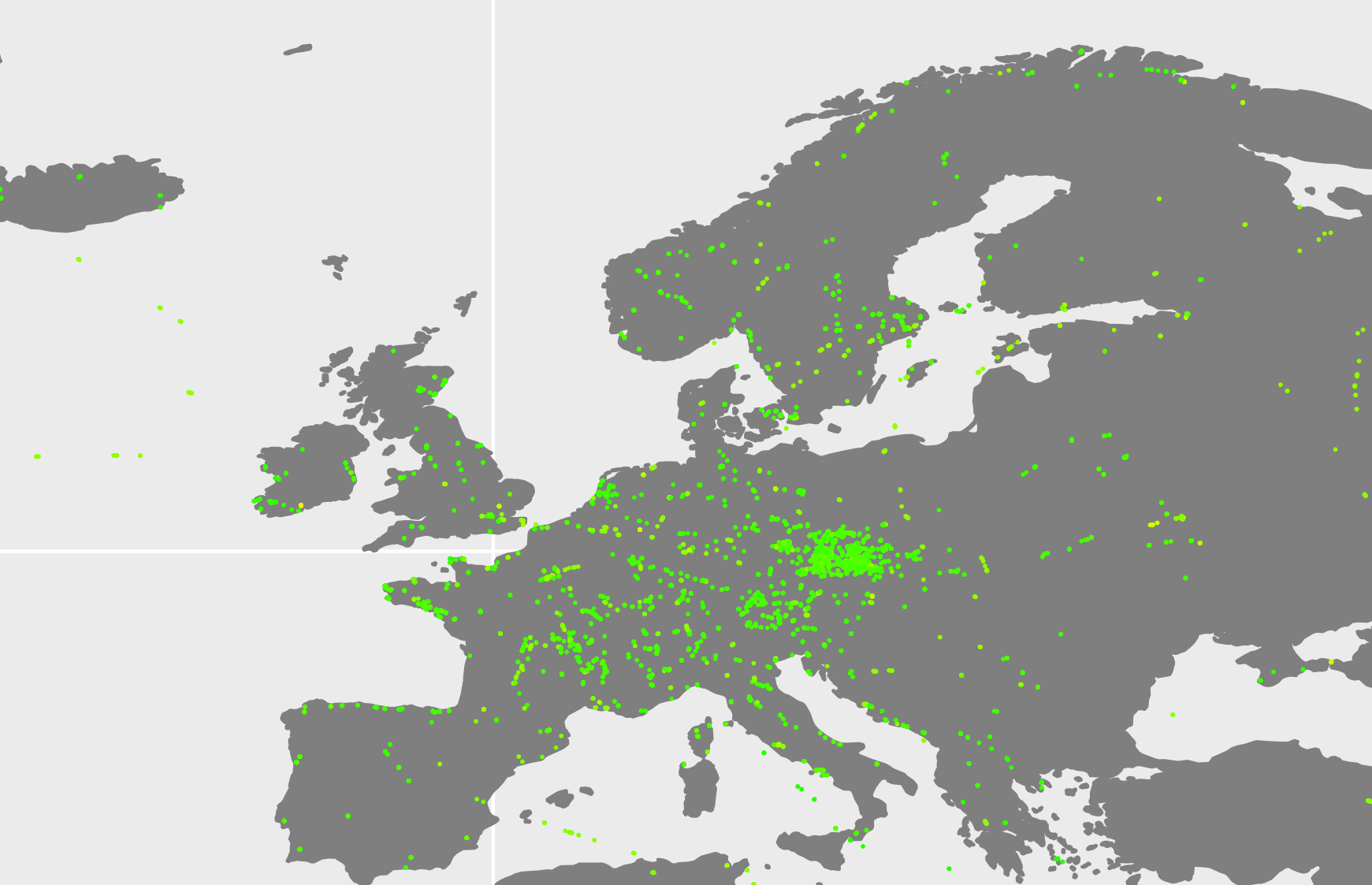
During the PRACE Summer of High Performance Computing programme I am working on big data using RHadoop. The data set is a set of 80 million ionizing radiation level measurements in the world. To explain everything clearly, I have to do a little introduction.

Beautiful evening near Ljubljana castle.
Theory
First of all we have to see the difference between types of radiation. We can divide them into two basic types:
– Non ionizing radiation – electromagnetic radiation that does not carry enough energy per quantum to ionize atoms or molecules.
– Ionizing radiation – carries enough energy to liberate electrons from atoms or molecules, thereby ionizing them.
Ionizing radioactivity can be both our ally and enemy – it all depends on the size of the dose. It comes from the cosmos, industry, mines and even from another person. It is also very useful tool in medicine. There are many treatments based on ionizing radiation such as x-rays or computed tomography.
In most types of examinations connected with it, the value is so small that it requires hundreds or thousands of repetitions to threaten our health. The most important thing for us to know, is how much radiation can we receive.
There are many units describing radiation level (Rad,Gray,Curie,Sievert) – I will use Sieverts ( 1Sv = 1J/1Kg).
Exposure to 100 mSv a year is the lowest level at which any increase, is clearly evident a cancer risk. For example, a chest x-ray provides only 20 µSv, while a mammogram procedure provides 3.0 mSv.
People have contact with radiation every day in many fields. Yearly dose for natural potassium in the body is 390 µSv and even eating one banana is connected with a dose of 0.1 µSv.
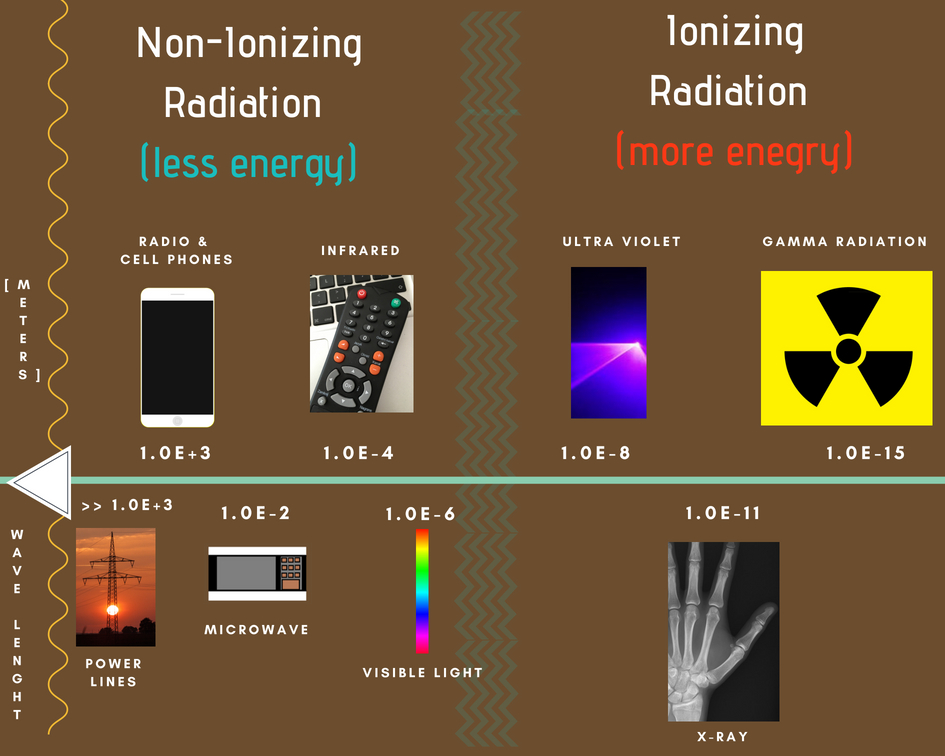
Dependence of wavelength on energy
HPC adventure
We’ve installed RHadoop software on the HPC infrastructure which allows to manage really huge data. In my case, the text file has 10 GB of data, but RHadoop is ready to manage much bigger files. In the data set there are radiation measurements provided by a volunteer science project – ‘SAFECAST’.
What I intend to do with the data set is to use clustering algorithms to detect most frequent regions with high level of radiations. Different clustering algorithms process the data from many sides – for example we can check the highest (lowest) radiations levels only in January.
We use RHadoop which allows for concurrent processing. Primarily, a master-node divides the data into smaller, independent chunks. Then each worker node works on one of them. It uses a Map function which performs filtering and sorting. The next step is Shuffle – worker nodes redistribute data based on the output keys. The output goes to the Reduce function which processes each group of output data, per key, in parallel.
So What’s next ?
I am planning to use machine learning ideas to support clustering algorithms and to make an independent way of research. To be honest – I can’t wait to compare the results !
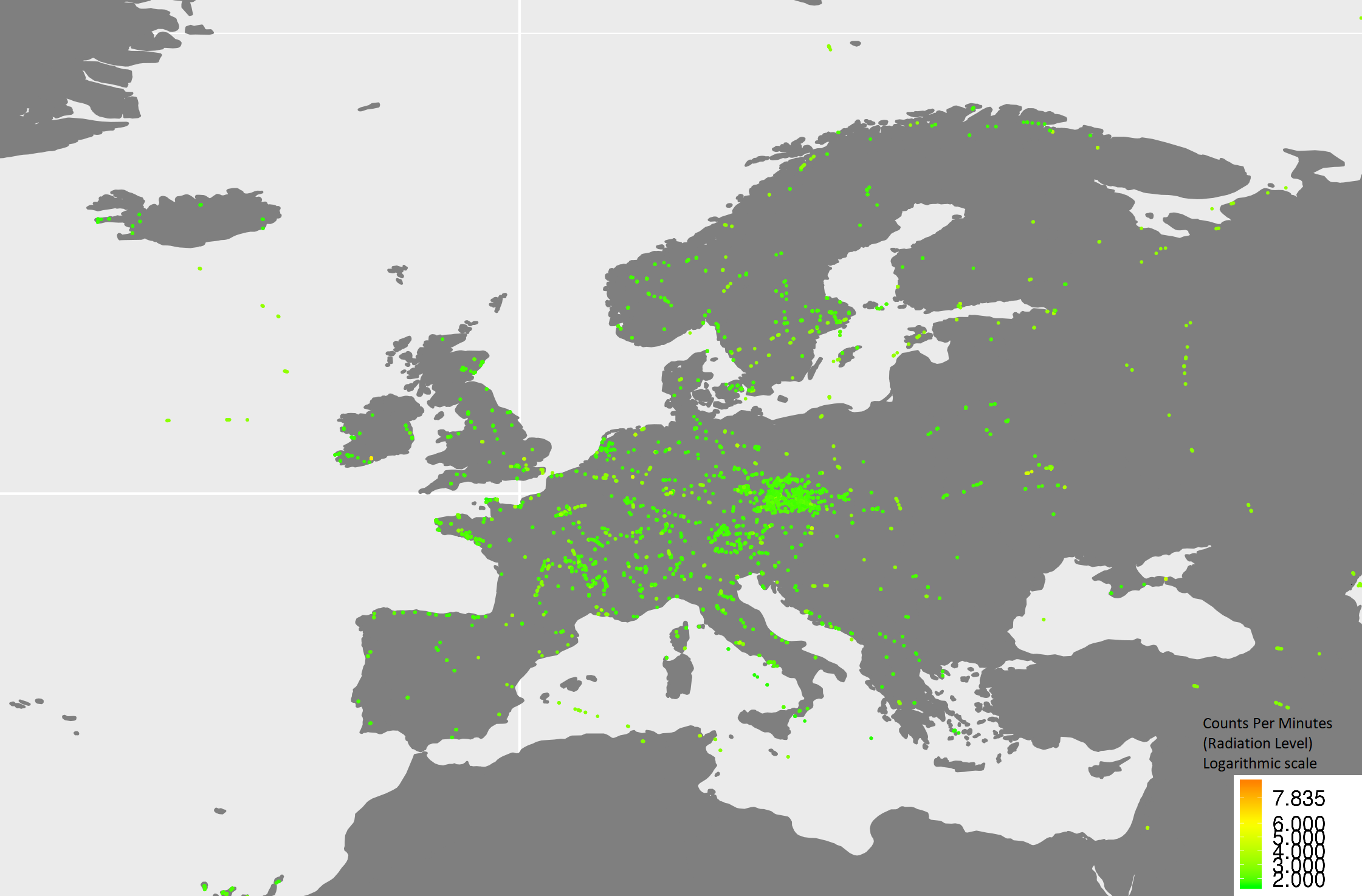
Some of the first results of Hadoop processing. European places and CPM (Counts Per Minute – another radiation unit) values in logarithmic scale.
I am a student at Poznań University of Technology in the field of Computer Science. In september I'm going to start my last semester of BSc. In a nutshell, I'm a geography and floorball lover. Never too tired of trying something new (isn't life all about trying new things?). I've also have quite an unusal hobby, which is tracking the Polish football league (if you don't understand why it's unusual, check out our result in the World Cup). I'm fond of creating new things and wondering if they can work better. That's why I am into science. I'm currently making my very first steps in international education with Summer of HPC and can't wait to see where it's going to lead me.

The article is truly wonderful! Best of luck with the project Marcin. You got this buddy!
This is awesome! I think you should create more articles like this one. Good luck!
Good job!
Very informative article Marcin! Thanks for that 😉