Adrián Rodríguez Bazaga

Hello there, my name is Adrián Rodríguez Bazaga and I’m a 21 years old guy from Valencia (the home of the Paella!), but I come from the beautiful island of Tenerife in the Canary Islands, Spain. This is where I just finished my Bachelor’s Degree in Informatics Engineering at the University of La Laguna. In September of this year I will be travelling to Barcelona to pursue my Master’s degree in Innovation and Research in Informatics with the specialization on Data Science and Machine Learning offered by UPC (Polytechnical University of Catalonia).
-
Me at the President Garden in Bratislava
Throughout my degree I learned many things about the world of technology, arousing my curiosity in certain fields of Computer Science. Specifically, I am very interested in Data Science (Data Mining, Knowledge Discovery), artificial intelligence (Machine Learning, heuristics), Bioinformatics (Genomics, etc.), parallel algorithms and High Performance Computing (HPC). To obtain conclusions from data sets that initially seemed to have no value is something that strikes me; including the part of data analysis, mathematical statistics and Deep Learning, since it provides a potential tool that can be used to make important decisions.
In 2016, I had the opportunity to work as a research intern at a renowned research institution, where I worked on a project in the field of Big Data: RDF processing solutions through Big Data for the discovery of relationships between concepts in the DBpedia. Also, from December 2016 until June 2017 I worked on a research project at a research group at the University of La Laguna, thanks to a grant by the Spanish Government. Specifically, the project was called ‘Exploiting Open Data sources through Data Mining, classification and regression techniques with Spark to analyze traffic flow’, where we propose the use of Data Science and Machine Learning techniques with Apache Spark. The use of techniques such as decision trees and multilayer perceptrons for the prediction of road traffic congestion level, focused on the road network that connects the container terminal of Tenerife’s port to the highway’s access. This is important to look at as it is the main traffic bottleneck when delivering products inside and outside of the port.
In June 2017, I finished my final degree project: ‘Heuristics and Big Data in mathematical optimization problem: extension to the Tourist Trip Design Problem’, where my objective was to solve a problem that by definition is NP-hard using an artificial intelligence approach. Specifically, approximate algorithms (heuristics) such as GRASP with LRC, among others were used. Furthermore, I had to work with data from different datasets and link them (Linked Data). All of them together were used to try to gather information about every point available on the Earth. So, we are talking about a volume of more than 100 million instances (the so-called Big Data concept).

My interests are still greater, I’m interested in learning, researching and developing tools that allows to improve medical applications using Data Science, which is my current interest: Bioinformatics. This interest was motivated, among other reasons, by my visit to the ITER Supercomputing Center, where the TEIDE HPC supercomputer is hosted (the second most powerful in Spain), and where IonGAP (an integrated genome assembly platform for Ion Torrent data) is used as part of a chain of tools to research on genomics, and Data Mining for medical diagnosis. Medical data mining has a great potential for exploring the hidden patterns in the data sets of the medical domain, which can be utilized for clinical diagnosis. Taking into account that available raw medical data are widely distributed, heterogeneous, and voluminous, my interests are to collect that data in an organized form to build medical information systems that can help to reduce the huge rate of deaths that can be prevented if a diagnosis can be made in time. To make this possible, we need to use a High Performance Computing (HPC) approach, which mostly refers to the practice of aggregating computing power in a way that delivers much higher performance than one could get out of a typical desktop computer or workstation in order to solve large problems in science, engineering, or business.
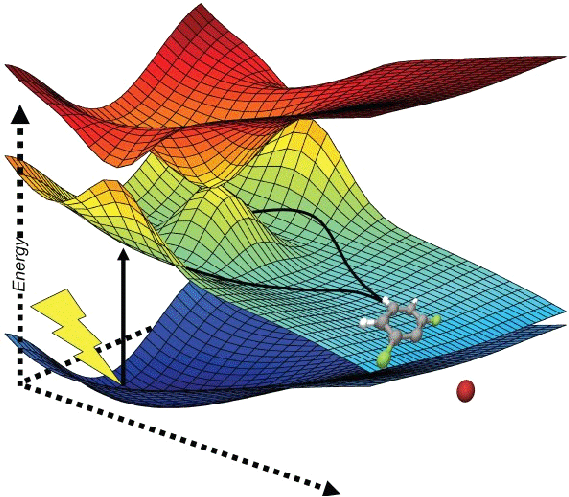 During this summer, thanks to the PRACE Summer of HPC programme, I will be working at the Computing Centre of the Slovak Academy of Sciences, on the project “Apache Spark: Are Big Data tools applicable in HPC?” where my objective is the implementation and optimization of the routinely used quantum chemistry Hartree-Fock method in Scala with Spark and in C++ with MPI to perform some benchmarking. Other quantum chemistry algorithms such as Density Function Theory and Second-order Møller-Plesset perturbation will be also looked into, so I’ll need to deal with the quantum many-body theory, trying to bridge HPC with the Big Data world, and resulting in visually appealing outputs such as molecules, orbitals, among others.
During this summer, thanks to the PRACE Summer of HPC programme, I will be working at the Computing Centre of the Slovak Academy of Sciences, on the project “Apache Spark: Are Big Data tools applicable in HPC?” where my objective is the implementation and optimization of the routinely used quantum chemistry Hartree-Fock method in Scala with Spark and in C++ with MPI to perform some benchmarking. Other quantum chemistry algorithms such as Density Function Theory and Second-order Møller-Plesset perturbation will be also looked into, so I’ll need to deal with the quantum many-body theory, trying to bridge HPC with the Big Data world, and resulting in visually appealing outputs such as molecules, orbitals, among others.
