Anomaly Detection With LSTM Autoencoders for Time Series Data

Anomaly detection
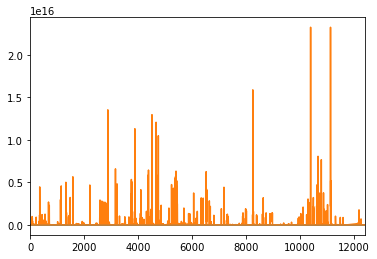
Anomaly detection is the process of accurately analyzing time-series data in real-time, identifying unexpected items or events in data sets, which differ from the norm (no anomalies). Also, it can be an extreme case of an unbalanced supervised learning problem, as the vast majority of data generated by real supercomputers is, by definition, normal. In today’s world, the issues concerning their maintenance are increasing by rapidly becoming larger and complex the High-Performance Computing (HPC) systems. Anomaly detection can help pinpoint where an error occurs, enhancing root cause analysis and quickly getting tech support before reaching a critical state.
LSTM Autoencoders
Autoencoder is an unsupervised learning technique capable of efficiently compressing and encoding data and reconstructing the data from the reduced encoded representation to a representation close to the original input as possible. For using Autoencoder for anomaly detection, we first train an Autoencoder on normal data, then take a new data point and reconstruct it using the Autoencoder. If the error (reconstruction error) for the new data point is above some threshold, we label the example as an anomaly.
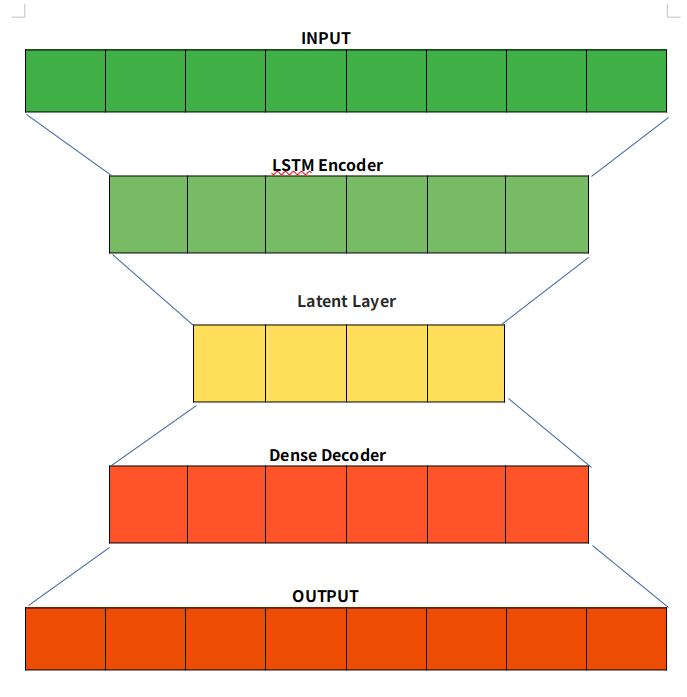
The bottleneck or Latent layer is the layer that contains the compressed representation of the input data. This is the lowest possible dimension of the input data.
For anomaly detection, we used an LSTM autoencoder that is capable of learning the complex dynamics of long input sequences. We used data sets that are currently being collected by ExaMon on several supercomputers atCINECA, in particular the current tier-0HPC system, Marconi100. To learn more about the data set we used, you can check my colleague’s post about it.
