Exiting news from Python – Let’s do HPC!

As stated previously, after searching for possibilities to accelerate our Python programs, we now summarized the results for you! First, in a serial form and second, in parallel. Come and check it out! It could provide you with information you need to combine HPC and Python
Serial programming and the time in seconds per iteration
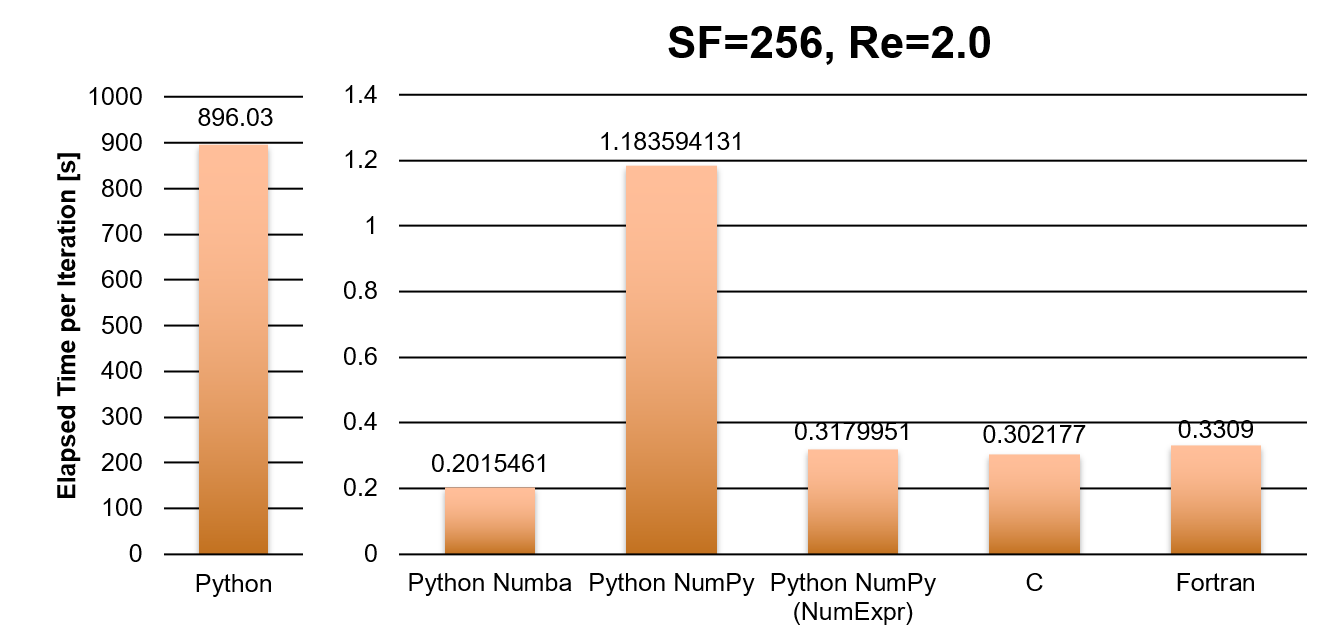
Look how slow the naive Python version is, we even had to adjust the graph. The NumPy version is nearly 800 times faster than naive Python, and the performance of NumPy version after NumExpr optimization improves greatly, even compared to the performance of C and Fortran versions. This indicates that NumExpr has a good optimization for NumPy arrays calculation at this problem size. In comparison to the serial CPU versions of the CFD program, the implementation of the GPU-based Python Numba is 6 times faster than the NumPy version and even slightly faster than the C and Fortran versions. It is important to ensure that the data copying from CPU to GPU and back is minimised.
The boundaries for the serial programming are now clearer. Due to the fact that we work on a computer cluster, we should use its potential and spread out our code to multiple cores and maybe also nodes!
Split the work and run in parallel!
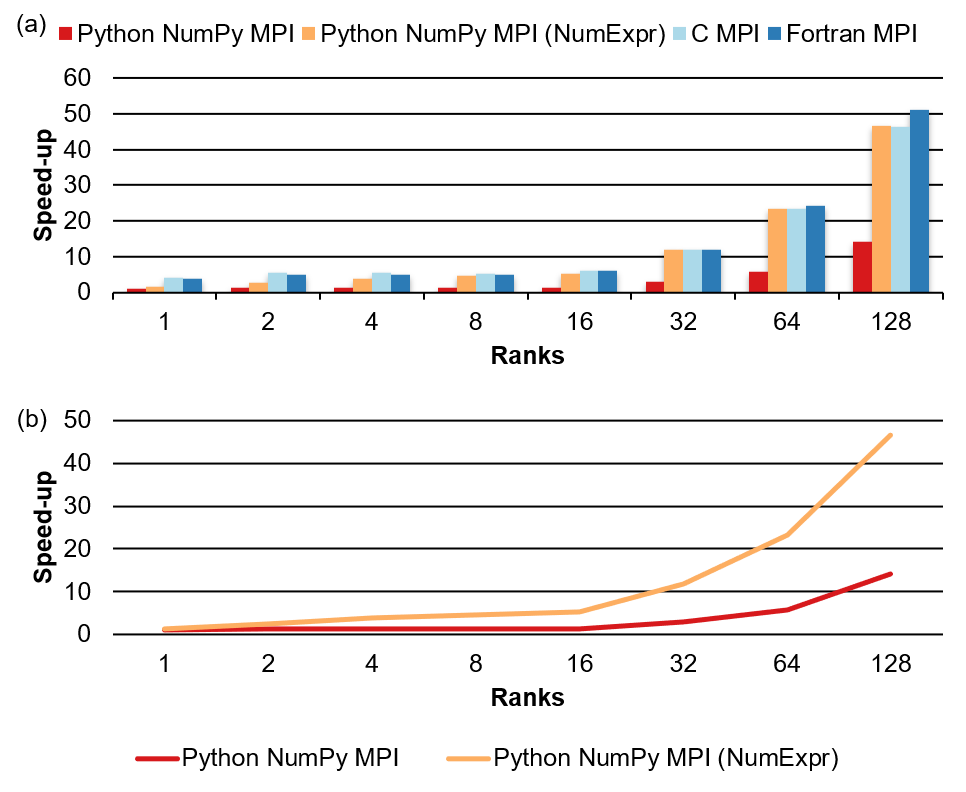
Overall, the speed-up of all parallel programs increases with the number of ranks. For the Python programs, the performance improvement is small with a small number of ranks (1 to 16), as well as for C and Fortran. The NumExpr optimized version is close to C and Fortran at 16 ranks. In the case of a large number of ranks (32 to 128), the performance of all programs improves significantly. The Python NumPy MPI consistently lags behind the other three, while the performance of NumExpr optimized version is still close to C and Fortran. We see that after more than 16 ranks, the scalability of the NumExpr version is better than non-NumExpr version.
.. going even further with unreleased information (only here):
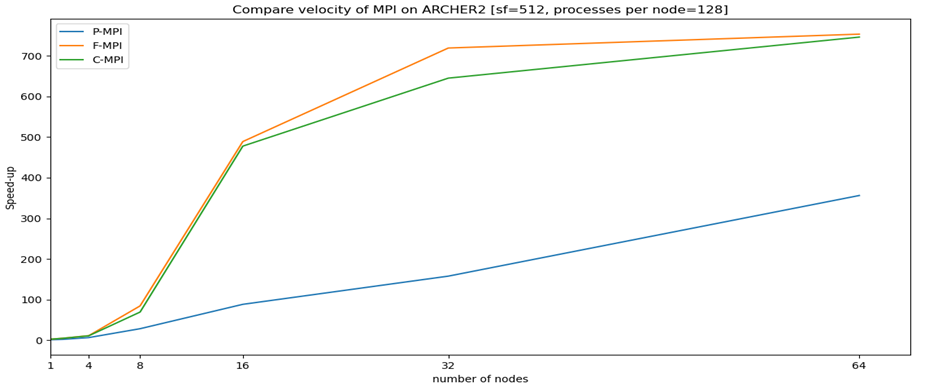
The results are given in comparison to the time spent for one iteration with Python MPI on just one full node (128 processors). Interesting is that the speed up is super-linear for all the versions. With using 64 nodes on ARCHER2, we accelerate Python MPI by a factor of 356x in relation to using one node. Fortran and C are around 750 times faster! We still think the Python MPI results are quite convincing. If you are interested in more results, you are welcome to leave a comment!
After all the reading, check out our short summary video:
Thanks for enjoying the blog. See you next time to more HPC events?!
Thanks to David Henty and Stephen Farr for the huge support and making the project so interesting! And of course to Jiahua, my partner during the Summer of HPC!
Great job PRACE and SUMMER OF HPC organizers!
PhD candidate at University of Limerick | DAFINET group | carving out a network theory of attitudes
