Help! The Beatles became XML!
A markup language is a mechanism to add labels to a text to define a structure of the document. The copy editors did that long time ago to give instructions to the typesetters. Now, all these tasks are computerized, and those “instructions” are referred to as “tags”. Examples of markup languages are XML and LaTeX.
XML (Extensible Markup Language) defines a set of rules to encode documents but it is also used for the representation of data structures. I will write about the latter, which is the one I used in my project. The best way to understand it is through a simple example:
The Beatles
1965
10.89 €
English
United Kingdom
Pop rock
34:20
Queen
1975
16.63 €
English
United Kingdom
Hard rock
Progressive rock
43:10
The Who
1965
16.51 €
English
United Kingdom
Rock
Pop
Hard rock
36:13
Listing 1. Example of a data structure in XML
In this example we have a data structure of a collection of CDs. Every CD has its own information: title, artist, year, price, … You can make up the labels. I could have written “<tag>” instead of “<title>” but “title” is easier to understand, isn’t it? It is not necessary to have all the same tags for all CDs; for example, the first CD has just one genre, the second has two and the third has three.
qwqw
XSLT does not mean “eXtra Super Large blog posT” as you may think, it means “eXtensible Stylesheet Language Transformations”. It is a language for transforming XML documents into other kinds of documents. You can transform XML to PDF, PNG, etc. and even to another XML document! But… Why do we want to transform an XML document to another XML document if it is already in XML? For example, to create a simpler XML document including less information so it is easier to process afterwards.
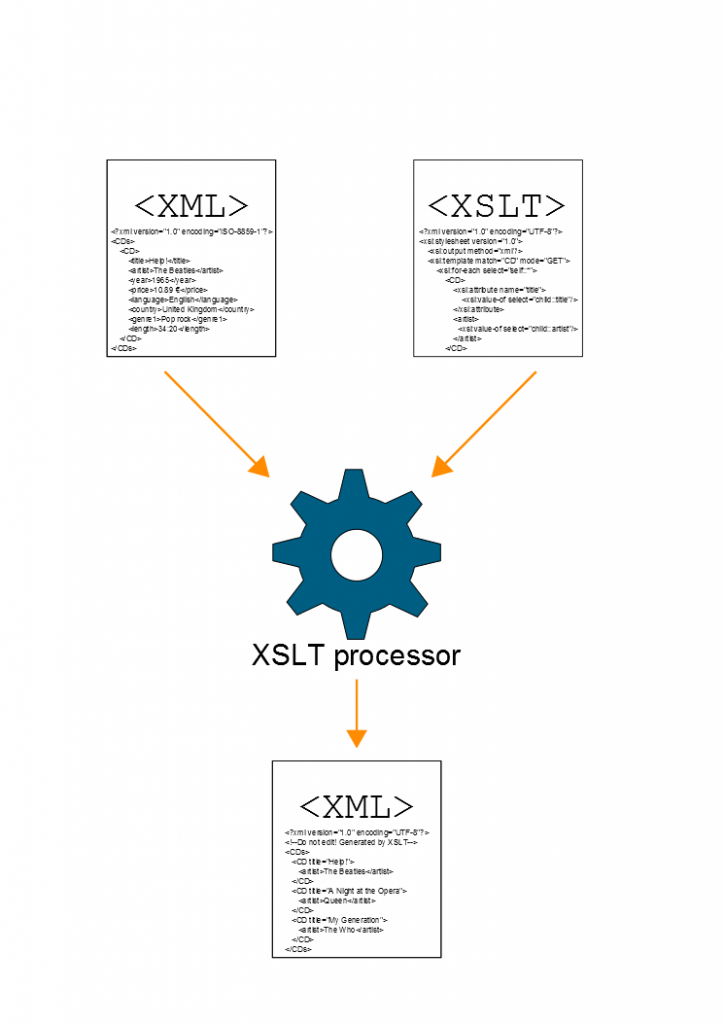
The XSLT processor takes one or more XML source documents and one or more XSLT stylesheet modules, and processes them to produce an output document. The XSLT stylesheet contains instructions that guide the processor to produce the output document. As illustrated in Figure 1.
So, let’s summarize how it works with a simple example, using the previous XML document in Listing 1 as input.
Do not edit! Generated by XSLT
Listing 2. Example of a XSLT stylesheet
Listing 2 is the XSLT stylesheet that contains one template. This template iterates over all the CDs. For each one it creates an attribute named “title” and gives it the value of the tag title of the selected CD.
It is quite easy to read and understand the code: trying to explain it in words, I used some of the XSLT instructions (I marked them in red).
The Beatles
Queen
The Who
Listing 3. Example of output in XML from XML and XSLT
Listing 3 shows the resulting output after processing the XML and the XSLT stylesheet. Now we have a simpler data structure. The purpose of the XSLT was to create another data structure in XML with the information needed and in a different format.
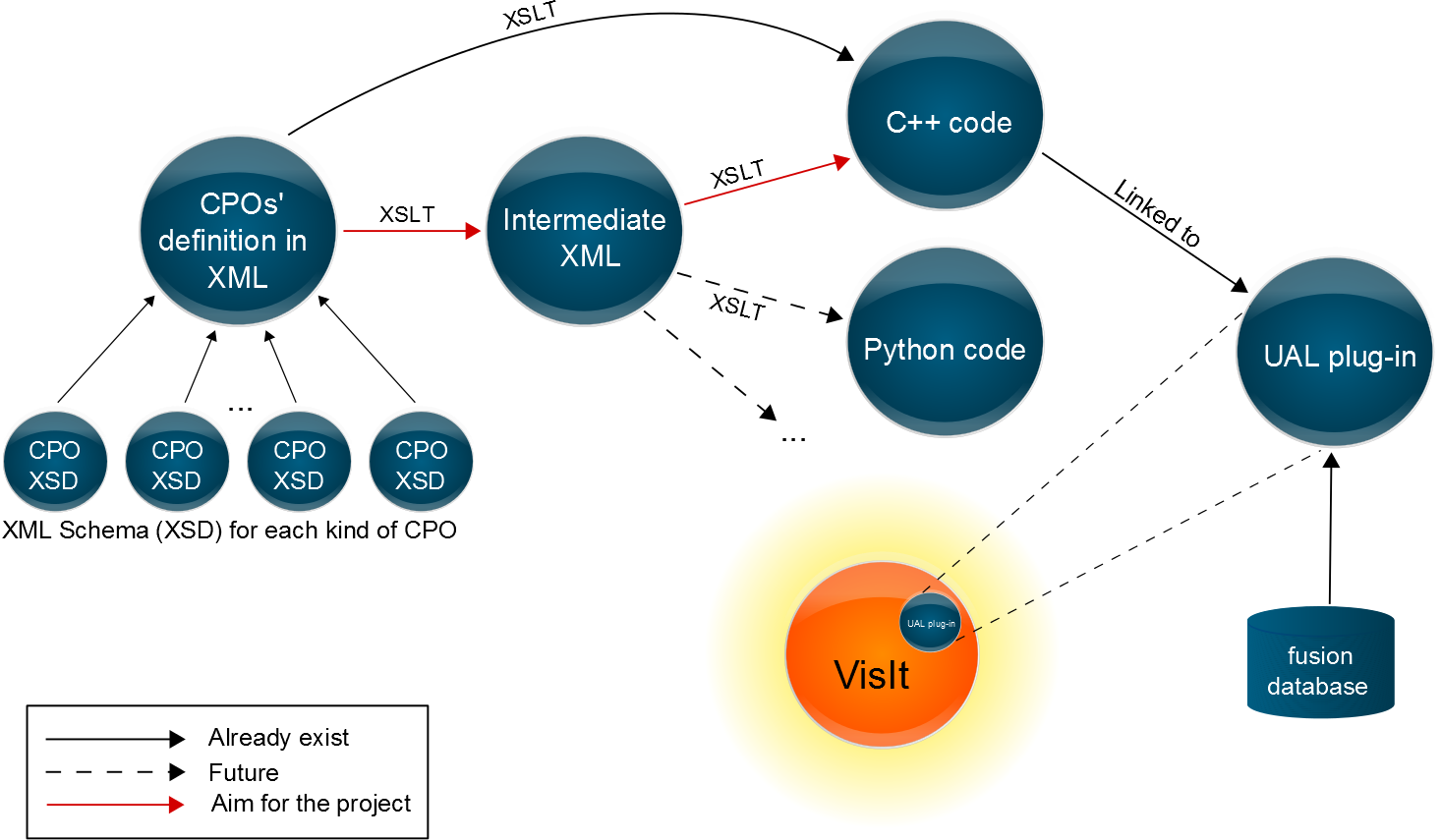
Ok, but how is that related to my project? Actually, I did pretty much the same. Instead of CDs I had Consistent Physical Objects (CPOs): data structures that describe various physical aspects of fusion experiments. There is already a translator from XML to C++ written in XSLT, but we also want to translate it to other languages such as Python. The problem is that creating a whole new XSLT for every target language is too complex. So, I wrote an XSLT to transform the XML containing the CPOs description to a simple XML with just some attributes for selected CPOs. The result is that now the previous XSLT that transforms to C++ still works and it will be easier to create an XSLT to transform it to other languages. In Figure 2 there is a diagram of the process and how that relates to our visualizations with VisIt.
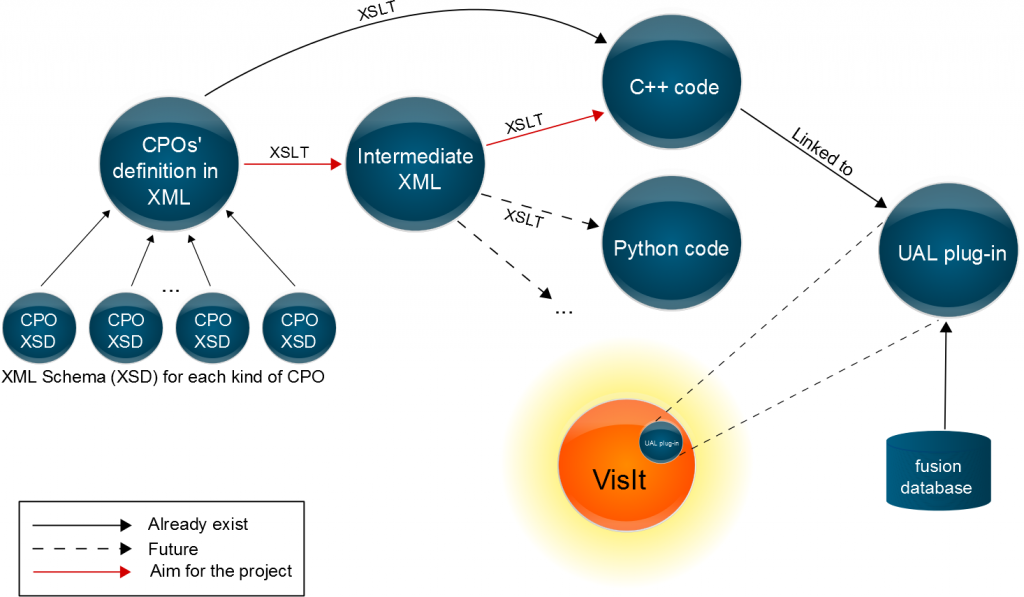
Figure 2. File diagram of the VisIt plug-in
I will explain in the next post what the VisIt plug-in is, and what I added to it!
If you are dizzy because of all these “strange” words, you must listen this song (and the lyrics if you need them)!

i couldn’t see that where is the hpc?
amazing!!
Easy to read and understand, and entertaining examples. Good job!
Dear Patrik,
First of all, thank you for your question!
I explained that in my previous post, if you want to take a look:
https://summerofhpc.prace-ri.eu/if-you-can-visualize-the-shape-you-can-understand-the-system/
The XML document management and transformation using XSLT is part of a plugin for UAL plugin for VisIt. All these pieces compose the software framework used to visualize nuclear fusion simulations. Both the fusion reactor simulations and the visualizations are carried out in HPC systems. And this is why HPC is important because large simulations and the visualization of large data sets coming out of these simulations are unfeasible even in high-end desktop computers.
I’m adding and fixing functionalities to the UAL reader plug-in for VisIt. I will give more details about the plug-in and show the kind of visualizations it allows in my next post!
—
Dear Teresa and arc46: thank you for your feedback! 🙂
Easy to understand good job!!! see you soon !!Moon!
Easy to understand even for me! Good disc selection too! Kisses, Laura.
Good explanation!
very good job … I congratulate you!
I get the feeling that it is a tool that can make easier the implementation of big data.
Easy to understand… even for me! Thanks