How many GPUs does it take to recognise a dog?

In my last post, I gave a quick overview of the challenges involved in benchmarking deep learning algorithms and hardware as well as my plans to make a tool for this task to be used on UniLu’s Iris Cluster.The main development since then is that I now have a version of this tool up and running. What it does is let the user import a model and dataset and supply a config file with details of the training before it automatically distributes everything it across the hardware specified, trains it for a while, and collects data on how quick and efficient the training may or may not have been. There’s also a script to sort parse the config file and produce a suitable SLURM batch script to run everything for when you’re feeling lazy.
As mentioned in the last post, there’s a lot of tweaking that can be done to parallelise the training process efficiently but, after a bit of experimentation and reading up on best practice, it looks like I have found default settings which work as well as can be expected. The general consensus on the subject is well summed up in this article but the short explanation is to keep the batch size per core fixed and adjust other parameters to compensate. Currently the frameworks supported are Tensorflow distributed with Horovod, Keras (distributed either with Horovod or the built in, single node multi-gpu-model functions) and Pytorch. While this is by no means a complete list of all the deep learning frameworks out there, it’s enough for me to step back and see how well they work before adding more.
Now that I seem to have working code, the natural thing to do with it is to run some experiments for a sample problem. The problem in question is image classification. More specifically training a neural network to distinguish between the different categories of image in the CIFAR-10 dataset. This is a standard collection of 32×32 pixel images (some of which can be seen in the featured image for this post), featuring 10 categories of object, including dogs, ships, and airplanes.
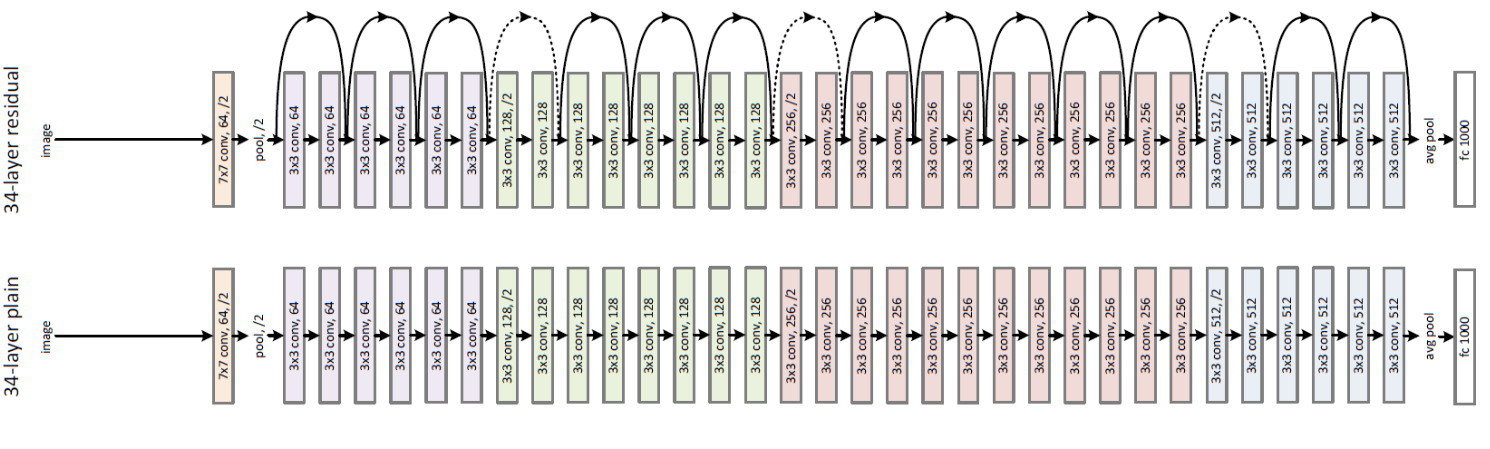
The neural network being used for these experiments is Resnet, a standard algorithm for this type of problem. The specific version being used has 44 layers and over 600,000 trainable parameters. While this sounds like a lot, training a network of this scale would be considered a medium sized task in deep learning. This is helpful because it means my experiments take a few minutes rather than hours or days to run but it should be noted that many state-of-the-art algorithms are a lot more complex.
The Results are in
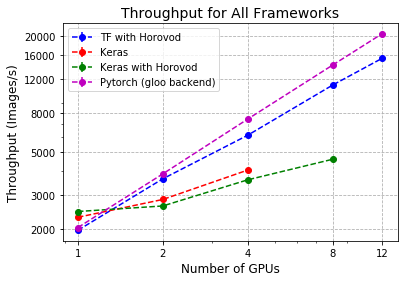
This is the section where I include a large number of graphs which came from the results of the experiments described in the previous paragraph. The first one, above, shows the average throughput (number of images processed per second during training) from when the model was fitted over 40 epochs (sweeps through the entire dataset) on varying numbers of GPUs. Metrics of this type are often used by chip manufacturers and organisations who build ML software to explain why their product is worth using.
The main trend which can be seen in this graph is that Tensorflow/Horovod and Pytorch both scale quite a bit better than Keras. This may not be unexpected given that Keras is the most high-level Framework considered and may have some hidden overheads slowing everything down. There’s also the fact that when using the built in Keras multi GPU functionality, only the training is split over multiple GPUs and not any of the other potentially time-consuming steps like loading and processing training data.
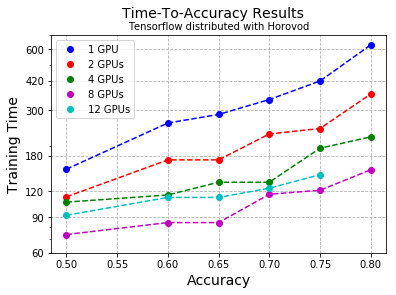
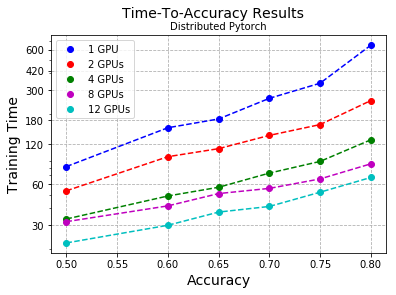
While looking at throughput is a very nice, mathematical way to work see how fast your setup is running, a metric which is more likely to help you decide what setup you should actually use is the time it takes for your model to reach a certain accuracy (which in this case is the proportion of images in the test set it guesses correctly). This is shown above for a range of accuracies for the two frameworks with the highest throughput. One trend which is visible in both cases is once 4 or more GPUs are used, the benefits of adding more start to look a bit limited. Note that Tensorflow seemed to actively slow down and didn’t reach the 80% mark in its 40-epoch run once 12 GPUs were used. This is likely due to the fact that the tweaks to make the code scale better, described in the first paragraph, have the effect of increasing the batch size (number of training examples processed at the same time) to the point where it becomes too large to train effectively. It also appears that the curves for Horovod aren’t quite as smooth as those for Pytorch. This might take a bit longer to explain than would be reasonable for one post but the short answer is that Horovod cuts some corners when handling weights for something called Batch Normalisation and this causes the accuracy to bounce around a bit early in a run.
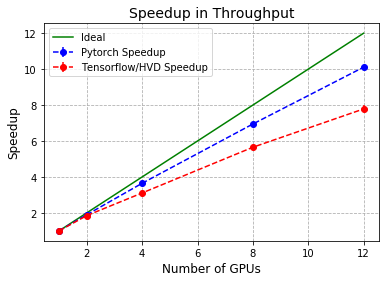
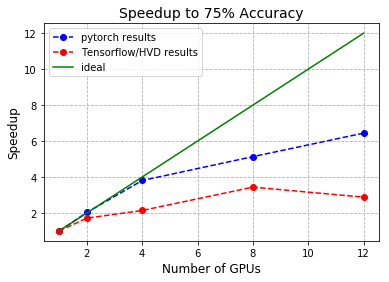
In the last of the graphs for this post, the speedup (1/walltime when using one GPU) is shown for both the throughput and time to reach 75% accuracy for the two best frameworks. In each case, these seem to reinforce the evidence seen so far that Pytorch scales better than the other frameworks considered. As can be seen, as far as throughput is concerned, both frameworks scale well for a small number of GPUs with discrepancies creeping in once more than 4 are used. However, it’s quite clear from looking at the difference in time to reach 75% that the changes to the training process needed to get decent scalability can slow down training and add to the inefficiencies caused by splitting the work over too many processors.
What comes next?
So now I have these initial results, the main question is what I do in the next three weeks I have left to make this project more interesting or useful. The first item on the agenda is to test the most promising Frameworks (currently Torch and Horovod) on larger problems to see how my current results scale. More comprehensive CPU only experiments could also be worthwhile.
Beyond running more experiments, the main priority, is adding support for a few more frameworks to the code. The standard built in method for distributed training in Tensorflow is currently in the pipeline. This could be interesting given that its perceived flaws served as Uber’s motivation for creating Horovod in the first place. Apache’s MXNet could also be making an appearance in future results, time permitting. Another important job from my last three weeks is to make this code a bit more general so it can benchmark a wider variety of tasks in a user-friendly manner. Currently everything is fairly modular but it may not be easy to use in tasks that are radically different from the one described above, so there’s still a bit more to be done to reduce the work needed for other users to use it once I leave.
