How to “Sparkify” code: Attack your for loops!
When dealing with Big Data, Apache Spark is an invaluable framework to parallelize computing workload across your cluster. In our project 2133: The convergence of HPC and Big Data/HPDA we are creating prototypical scientific applications that leverage both Big Data and classical HPC paradigms.
Much like in HPC, fors, whiles, recursiveness, and loops that can only be performed in serial are all bottlenecks that slow down the performance of your code. How can we use Spark to optimise these functions, and perform them across our dataset simultaneously in different cores?
If you are performing simple transformations, you are probably going to be able to get away with simple map -> reduce operations or default Apache Spark functions. Many of these are based in SQL and compatible with the two most popular data structures in Spark: RDDs (the base on which Spark is built) and DataFrames (which can be thought of as a table that works as a relational database with rich optimizations). You can find a great cheat sheet on these here! But what happens if you are trying to port some sort of complex code or transformation?
Enter UDFs and UDAFs. Spark User Defined Functions (UDFs) are a great tool that lets us perform more complex operations on data. Let’s pick an example from our own project.
We have 400 “.csv” files that we are importing into a Spark DataFrame, but unfortunately as we read them into just one DataFrame, we are losing the identifier of each frame on each row of data.
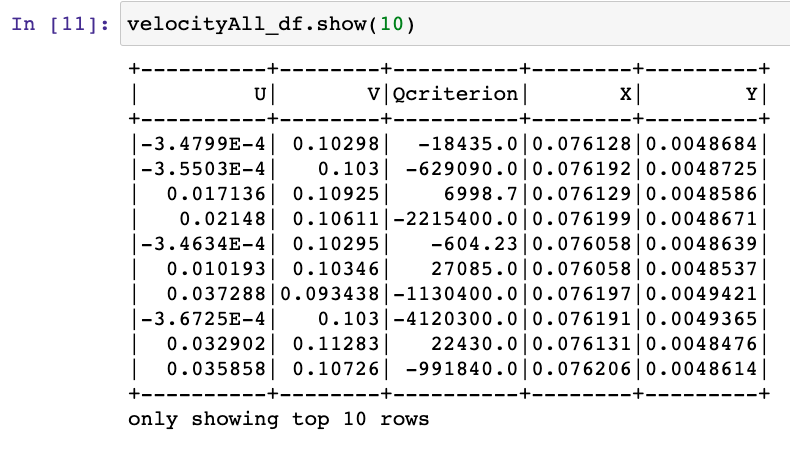
We now don’t know what frame (which in this case means point in time) each record belongs to, and the worst part is that we have over 1.8 million records! We could use a for loop, but that would take a very long time.

How can we try to solve our problem? Enter UDFs! We are going to create a UDF called “framenr” that stands for frame number. So what do we do with it?
Well we know we can obtain the frame number from the filename of the csv files in our directory. They are named as “velocity0.XXX.csv” where XX is the frame number.
To retrieve this we will create a UDF that maps lambda x (x is what we pass on to our function, our input is the file name), and then we will generate an integer by splitting this file name on the “.”, we then take “[-2]” that is the “second term from the back” from the split. What has happened here?
Well we split “velocity0.301.csv” for example into [“velocity0”, “301”, “csv”]. We can label the positions of this list of strings in Python as [0,1,2] or alternatively referencing them from the back as [-3,-2,-1], and we take position [-2] from this and convert it to an integer, we have our frame number!

We now want to add this as a column to our DataFrame, called velocity_df from the previous DataFrame we had called velocityAll_df, and we use the function “input_file_name()” which passes as a string the name of the file(s) the current Spark task is using. Let’s test this!

We now print the first 10 rows of our dataframe.
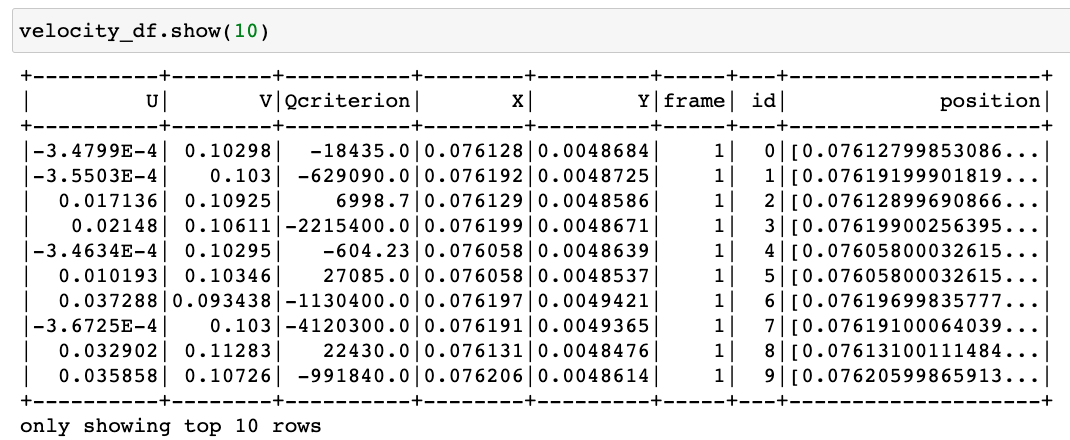
It worked! Feel free to ignore the columns id and position, these are extras for another post. Let’s see if we have the correct number of records for each dataframe…
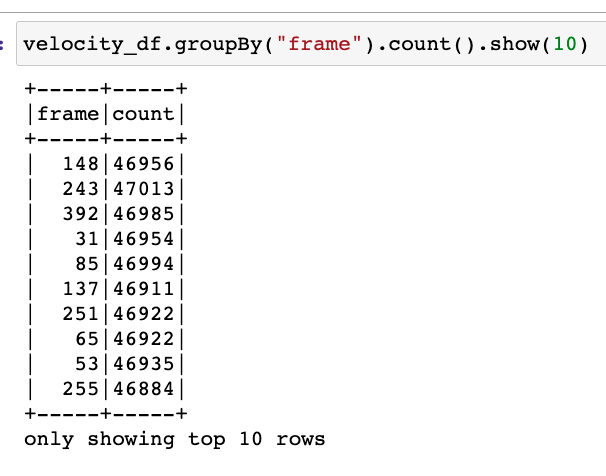
It seems we do! We should have close to 47000, the exact number depends on how the mesh was done on our original data, but that’s another story.
Hope you enjoyed the post, and keep HPC-ing!
