The last 100 meters

Hi everyone! So yeah, this will be my final post on the SoHPC page. It’s been quite fun participating in this program, but before saying farewell let’s talk about what I and @ioanniss managed to do this summer.
So, if you’ve read my previous post Making it work! you might have a rough idea what Project 2108 is about. In a nutshell, we have to modify an implementation of the Hartree-Fock algorithm by replacing a dense matrix-dense matrix multiplication, with a special sparse matrix-dense matrix multiplication. We expect that this step will have some effect on the runtime of the code.
We are doing the testing using a supercomputer from Žilina, Slovakia and we played around with different settings to see how this affect the runtime. The molecules used in these calculations are 5 different alkenes: C6H14, C12H26, C18H38, C24H50, C30H62, C36H74.

Firstly, we observed that the runtime is proportional to the cube of the size of the molecule, where we assume that the number of carbon atoms is equivalent with the size of the molecule. This is to be expected, since the most numerically intensive operations in the code are matrix-matrix multiplication, which scale with the cube of the size of the system.
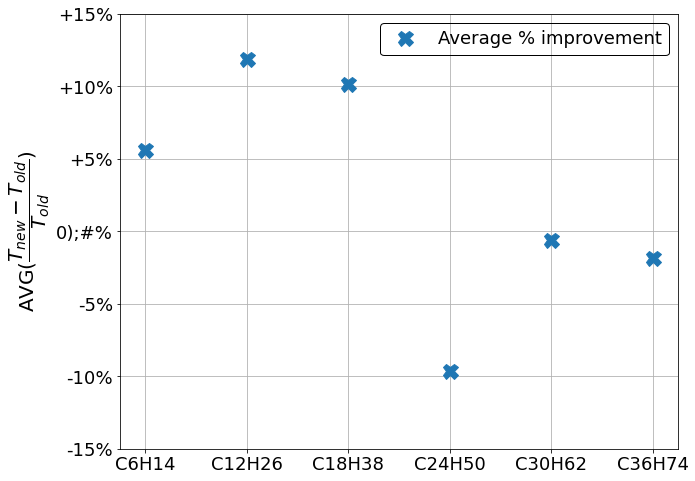
Following this step we decided to see if our new code is faster than the old one. We had 4 computing nodes at our disposal, each equipped with 32 cpu cores. We tested the runtime of the codes for 1, 2, 4, 8, 16 and 32 cores on one node. In the Figure 1. we can see the improvement in runtime for each molecule and in Figure 2. we can see the runtimes with different numbers of cores averaged for each molecule.
The results are not conclusive, but there’s a possibility that for large enough systems the runtime is slightly smaller. For this reason, we are still doing test, but with more basis functions than before. This calculations take quite a long time, but we hope we will have data on these systems to preset in the final report.
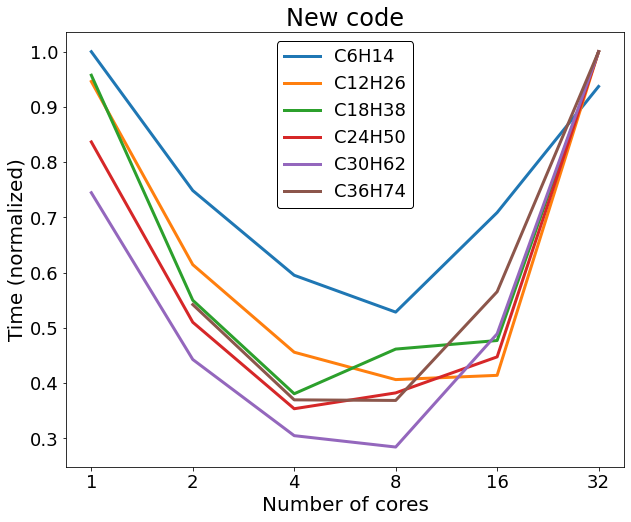
We decided to see also, how using different numbers of cores for the parallel calculation would affect the runtime of the code. As expected the code ran slowly on only a few cores, but it ran fastest not on 32, but 4 or 8 cores. This can be attributed to all the different cores trying to access the memory of the node, thus slowing down the code. Also the 32 cores are arranged in 4 cpus, so it’s not surprising that the runtime is very good for 8 cores. These results are condensed in Figure 3.
Finally we are also studying how using multiple nodes for the same calculation affects the runtime, and how the sparsity is linked to the performance of our new code. Hopefully we can do everything we set out to do until the deadline arrives, and I hope I will be able to show you some interesting results.
It was very pleasant taking part in this programme. My team was great, we managed to communicate quite often, and go forward with the project in quite a fast pace. I think we never really had any problems dividing our tasks, and Ján was always ready to help us. All in all it was a fun experience and I recommend SoHPC to anyone wanting to take part in a short scientific project for the summer. Finall thank you, the organizers for making SoHPC possible. Good luck with whatever you are doing and have a nice day!
