I’ve had it with these Motherlovin’ Bugs on these Motherlovin’ Multipoles!

My project has reached a turning point! What I’ve now got is an Multipole2Local segment of the Fast Multipole Method written in C++ using HIP and thus it runs on both AMD and Nvidia GPUs. The next step is to start implementing neat memory hacks and data reuse schemes to optimize the running time.
Most of my time wasn’t spent writing new code, but instead debugging what I had previously written. And I’ve had quite a number of those bugs. At least this many, accompanied with the appropriate reaction of course. To visualize this work, I could’ve taken screen-shots of the error messages, but instead I’ll seize this opportunity to show you what sorts of neat bugs I’ve found around the office!

Epilachninae Syntaxerronia in its natural habitat, the source code. They mark their territory with compiler errors, which makes finding them quite easy. This particular individual has made it’s presence very clear with in-line comments in the hope of attracting mates, but that also makes it more susceptible to predators.
I know what you’re now thinking: “What’s this ‘Multipole2Local’ anyway?” and “Wait a minute, you’re slacking off! Halfway through the program and you’ve only got one part!”. Don’t worry, I’ll address these issues right away!
The Fast Multipole Method consists of five separate phases: Particle2Multipole, Multipole2Multipole, Multipole2Local, Local2Local and Particle2Particle. As I mentioned in my previous post, the area in which we want to compute the potential is divided into small elementary boxes. The box division is done by dividing the whole area into eight smaller boxes and each of those boxes is again divided into eight smaller boxes and so on, until desired coarseness of the division is reached. The smallest boxes are called elementary boxes. You can then describe the whole structure using an octree.
- In Particle2Multipole phase, the spherical harmonics expansion of the potential function are calculated for each elementary box.
- In Multipole2Multipole phase, the individual potential function expansions of elementary boxes are shifted up the octree and then added up as the potential function of each parent box.
- In Multipole2Local phase, the far-field effects of several spherical harmonics expansions are converted into a local Taylor expansion of the potential function.
- In Local2Local phase, the Taylor expansions are added up and shifted down the octree. Now the far-field potential are represented as an Taylor expansion in each elementary box.
- Finally, in Particle2Particle phase, the near-field potentials are calculated classically pairwise.
The reason for working with just one segment of this algorithm becomes apparent from the following figure:
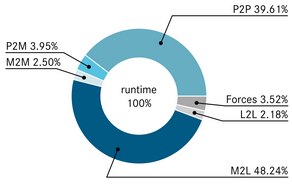
The runtime measurement of each segment of the algorithm [1].
A rare picture of Heterocera Segfaulticus. This nocturnal species is quite elusive, as they’re usually encountered during runtime, but its nutrition, liberal usage of memcpy and funky pointer arithmetic is found nearly everywhere. The large eyes are optimal for detecting tasty binaries in low-light environments.
The memory bandwidth acts as a bottleneck in this computation problem, which means that cutting down memory usage or speeding it up are the ways to increase the efficiency. There are now two ways to proceed: to look into the usage of constant (or texture) memory of GPU, which cannot be edited during computation kernel execution, but accesses to it are faster than in global memory. On the other hand, on the GPU we have FLOPSs in abundance so we wouldn’t need to store any data, if we could compute it on the fly. These are the approaches I will be looking into during the rest of my stay in Jülich Supercomputing Center.
In other news, I took a break from all of this bug-hunting and coffee-drinking and paid a weekend-long visit to Copenhagen, at another Summer of HPC site, where Alessandro and Konstantinos are working on their fascinating projects. Their workplace is the Niels Bohr Institute, which is the same exact building, where Niels Bohr, Werner Heisenberg and other legendary physicists developed the theory of quantum mechanics in the 1920s. And nowadays, the building is overrun with computer scientists; these truly are the end times.
The overall visit was a bit less about projects and a bit more about partying, though. In addition, we figured out how to run a Danish coffee machine and met a cool cat.

The Niels Bohr Institute in Copenhagen. Those vertical rails with some smaller sticks protruding out of them is a beautiful lighting setup which represents particle measurements at one of those enormous detectors at CERN.
References:
[1] I. Kabadshow, A. Beckmann, J. Pekkilä: Keep On Rolling. Pushing the Hardware Limits with a Rotation-based FMM, GPU Technology Conference posters, P7211, (2017).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nice work with the first bug photo! I really enjoy reading your colorful descriptions of otherwise mundane things.
Thanks! The first image actually took 15 minutes, 50 photos and lots of confuse-a-bug.
Cute Moth!
Optimization is fun!
I’ll be going to Copenhagen next weekend, I’ll have to read up on the local coffe machine infrastructure beforehand. Thanks for reminding
I hope your coffee intake didn’t suffer a hit during the trip. In Copenhagen they also had quite nice cafes, where there were trained staff to operate the machines, leaving you blissfully ignorant on the inner workings of such contraptions.