My story with Johannes

Don’t worry mum, Johannes is not my new Irish boyfriend! It is the computer I work with, and it is fantastic! Some of its hardware details are:
- Two Intel® Xeon® Processor E5-2643 (LINK): 4 cores @3.30 GHz
- 2 WD Caviar Blue (Hard Drives), 250 GB, 7200 rpm, SATA 3Gb/s
- 2 Seagate Barracuda (Hard Drives), 2TB, 7200 rpm, SATA 6Gb/s
- 2 NVIDIA K20 “Kepler” GPU cards
The name of this machine, Johannes, and the name of its GPU cards as well, is for the famous Mr Kepler, best known for his laws of planetary motion. The GPU cards are the latest generation of Tesla GPUs based on NVIDIA Kepler™, the world’s fastest and most efficient high performance computing architecture. Their features are:
- CUDA cores: 2496
- Peak double precision floating point performance: 1.17 Tflops
- Peak single precision floating point performance: 3.52 Tflops
- Memory bandwidth: 208 GB/sec
Johannes
I also work with Stoney, ICHEC’s supercomputer because it provides some nodes for GPU computing. These nodes have two NVIDIA “Tesla” (Fermi architecture) cards. One task of my project is to compare the performance of DL_POLY in both GPU cards: “Kepler” and “Fermi”.
Molecular Dynamics & DL_POLY
Molecular dynamics is a technique for computer simulation of interaction between atoms and molecules in a period of time. These simulations involve a high consumption of resources, both memory and CPU. Therefore, these applications are specially suited for HPC (High-performance computing) environments.
DL_POLY is a general purpose classical molecular dynamics (MD) simulation software developed by the Science and Technology Facilities Council (STFC) in Daresbury Laboratory, UK. The DL_POLY application has been parallelized using a Domain Decomposition (DD) strategy. Its name derives from the division of the simulated system into equi-geometrical spatial blocks or domains, each of which is allocated to a specific processor of a parallel computer. I.e. the arrays defining the atomic coordinates, velocities and forces, for all N atoms in the simulated system, are divided in to sub-arrays of approximate size N/P, where P is the number of processors, and allocated to specific processors, employing the Message Passing Interface (MPI) library for inter-process communication.
More recently, here in the ICHEC the code has been “hybridised” to exploit multi-core shared memory architectures (OpenMP) as well as Graphics Processing Units (GPUs). The existing parallel implementation of DL POLY is highly efficient and scales well to many thousands of CPU cores. Even so, my work in this project is to profile the application and try to improve the performance of the code for the latest NVIDIA Kepler K20.
For that, I use sophisticated profiling tools, TAU and NSight, to analyse the execution of DL_POLY and find possible pieces of code whose time execution can be improved. Then I have to modify some parameters and find which is the best combination of them.
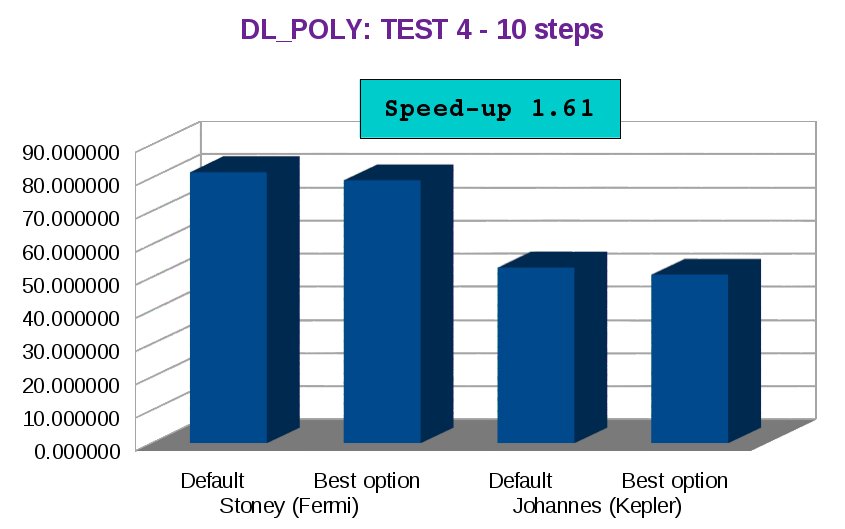
The following bar char shows the execution time for two different configurations of some DL_POLY parameters in both GPU cards: the first one is the default configuration and the second one is the CURRENT best configuration. As you can see the speed-up between the default option in Stoney (“Fermi” GPU architecture) and the best option in Johannes (“Kepler” GPU architecture) is 1.61! That means that the DL_POLY application is 1.61 times faster in Johannes than in Stoney, and this result can be better because I just analyse a part of the code!