Code. Run. Drink. Repeat. Parallel codes on HPC systems

Hello everybody!
I am really excited writing this blog post – I have some cool stuff I want to share with you.
If you missed last time’s post, I described what the project is about and mentioned one optimization for the serial Python code. Today’s topic – as the featured image reveals – is how code parallelization can be applied to accelerate a program.
Why to have parallel programs?
Imagine that you have to mop the floor in your house. Would it be faster if you did it all alone or if you got help from your family so that every family member mopped one room? If your answer is “Well, it depends…”, you are overthinking it. It is obviously faster to have more people (processes) mopping one room each (running the program with one part of the input).
Ways of parallelization
In this project, I have used MPI (Message Passing Interface) programming to parallelize the CFD (Computational Fluid Dynamics) simulation program I explained in my last blog post and achieve a speed up on CPUs. Additionally, I developed a GPU version of the program using CUDA programming. Now, let’s see how both of these programming models boost the performance of the CFD application.
Using MPI
One really effective way to speed up the program is by using MPI processes. Previously, there was only one process doing the whole work, i.e. the calculations on the entire matrix. Now, there are multiple processes each responsible for one strip of the matrix. These processes are working in parallel and produce one strip of the final image (matrix). In the end, these strips are combined to form the whole final matrix.
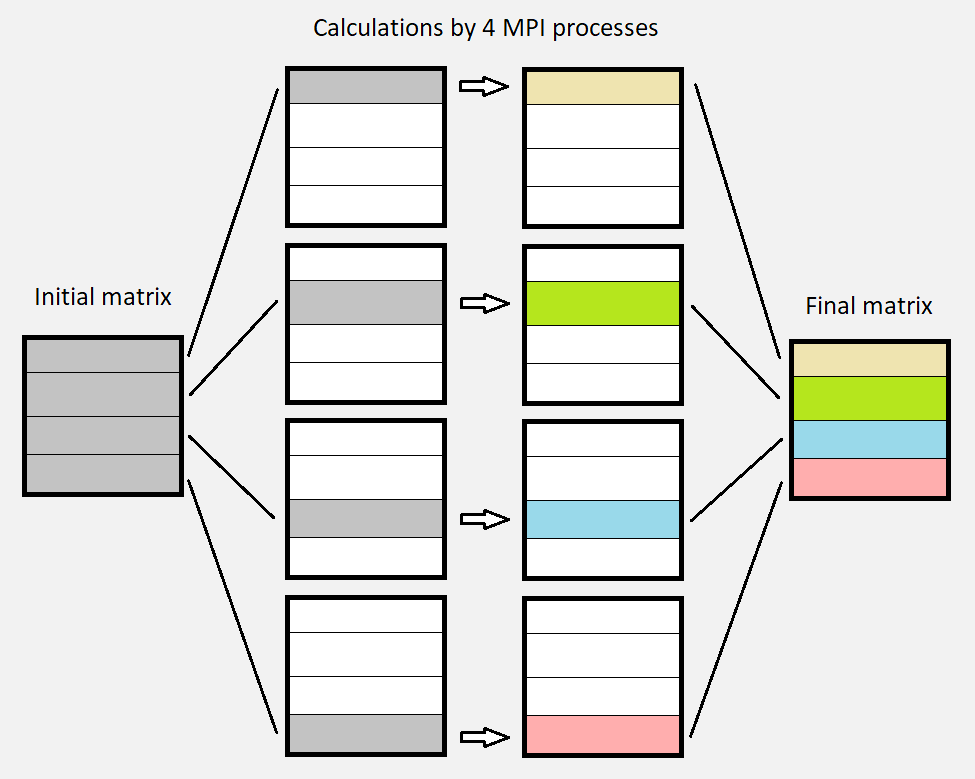

There is one detail for this technique to work properly. Because every point of the matrix uses the four neighbouring points to calculate its own value, there is an issue for the boundary points between two strips. This can be solved by sending data (messages) from one process to another.
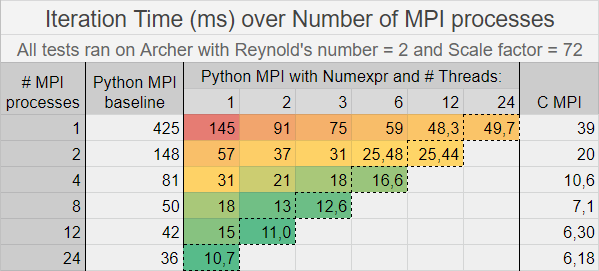
MPI programming model can be applied on both C and Python. So, I added MPI parallelization to the optimized Python code with numexpr module and compared its performance with the baseline Python MPI code and also the C MPI code. The conclusion of this performance analysis is that the numexpr MPI Python version is significantly faster than the baseline one and close to the C MPI. Moreover, it seems that the performance gain by increasing the number of threads is not as big as by increasing the number of MPI processes.
Using CUDA
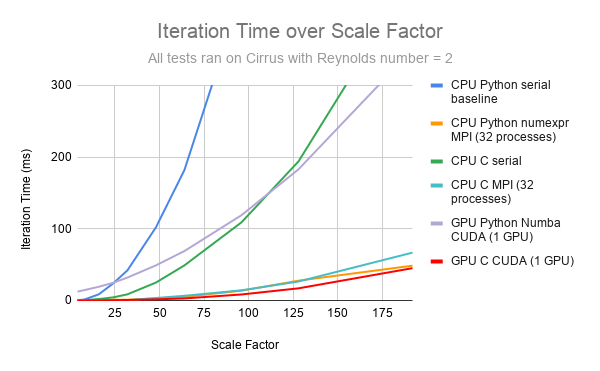
In recent years, there is a trend to use GPUs not only for gaming but also for general purpose, especially for programs that make few decisions but do many calculations. That’s a logical thought to make if you consider that instead of running tens of parallel MPI processes on the CPU, the GPU offers the ability to run thousands of threads in parallel. In our case, the optimal is to assign every point of the matrix to a separate GPU thread. The whole matrix is stored in the GPU’s memory, so any thread has direct access to any point of the matrix without exchanging any messages like MPI.
Python Numba CUDA
For the Python code, I have used Numba CUDA to implement and launch kernels (functions) on the GPU. Algorithmically, the procedure for each iteration is described by the following pseudocode:
for iterations number do
(step 1) calculate new matrix using the current matrix
(step 2) calculate error between current and new matrices
if convergence == true then exit ‘for’ loop
(step 3) copy new matrix to current matrix
end doThese steps have to be sequential because of the dependencies of the matrices. That means that all GPU threads executing one step in parallel have to finish before they continue to the next step.
Currently, Numba CUDA doesn’t support thread synchronization, except if the threads are in the same block of threads. But we need to synchronize every GPU thread and having just one block is not considered optimal. The only way to achieve synchronization between all threads is by launching a different kernel for each of the above steps. But this is not optimal either, because there is an overhead for each kernel launch. The ideal would be to launch just one single kernel to execute the whole ‘for’ loop instead of launching 3 kernels per iteration. That’s the reason why at this point I shifted from Python to C.
C CUDA
C CUDA offers the opportunity to synchronize all GPU threads, by considering them to be in the same cooperative group. In this way, the program can launch one single kernel and be fully optimized.
Conclusion and Question
I am excited to be part of this project and I am happy I made quite a lot of progress in the last few weeks. However, it is not always easy with programming. I’ve spent about 5 days debugging the C CUDA code. So, my question for you this time is:

What is the max time you have spent to debug a program?
Please, feel free to share in the comments your most intense debugging experience.
As always, thank you for reading my post. I am looking forward to seeing your comments.
