Report 2: Comparison using the final data

1. Introduction.
This project will be oriented to verify how a code related to the forecast of energy consumption is scaled from a local server to a supercomputer. This process will be implemented through Python and R in order to perform different actions required to fulfill the objective of the project.
2. Script used.
The script used has been modified in order to parallelize the code provided. Specifically, various techniques have been used, among which we can highlight the following:
- Mcapply: it is one of the simplest ways to parallelize the code and, therefore, one of the most commonly used.
- ParSapply: is a function that parallels the “sapply” method. This allows us to create a cluster from where the code can be executed.
- ParLapply: it is a function that allows us to use the “lapply” method in parallel. In the same way, it allows us to execute the code in a cluster (previously created).
3. Comparative with server and final data.
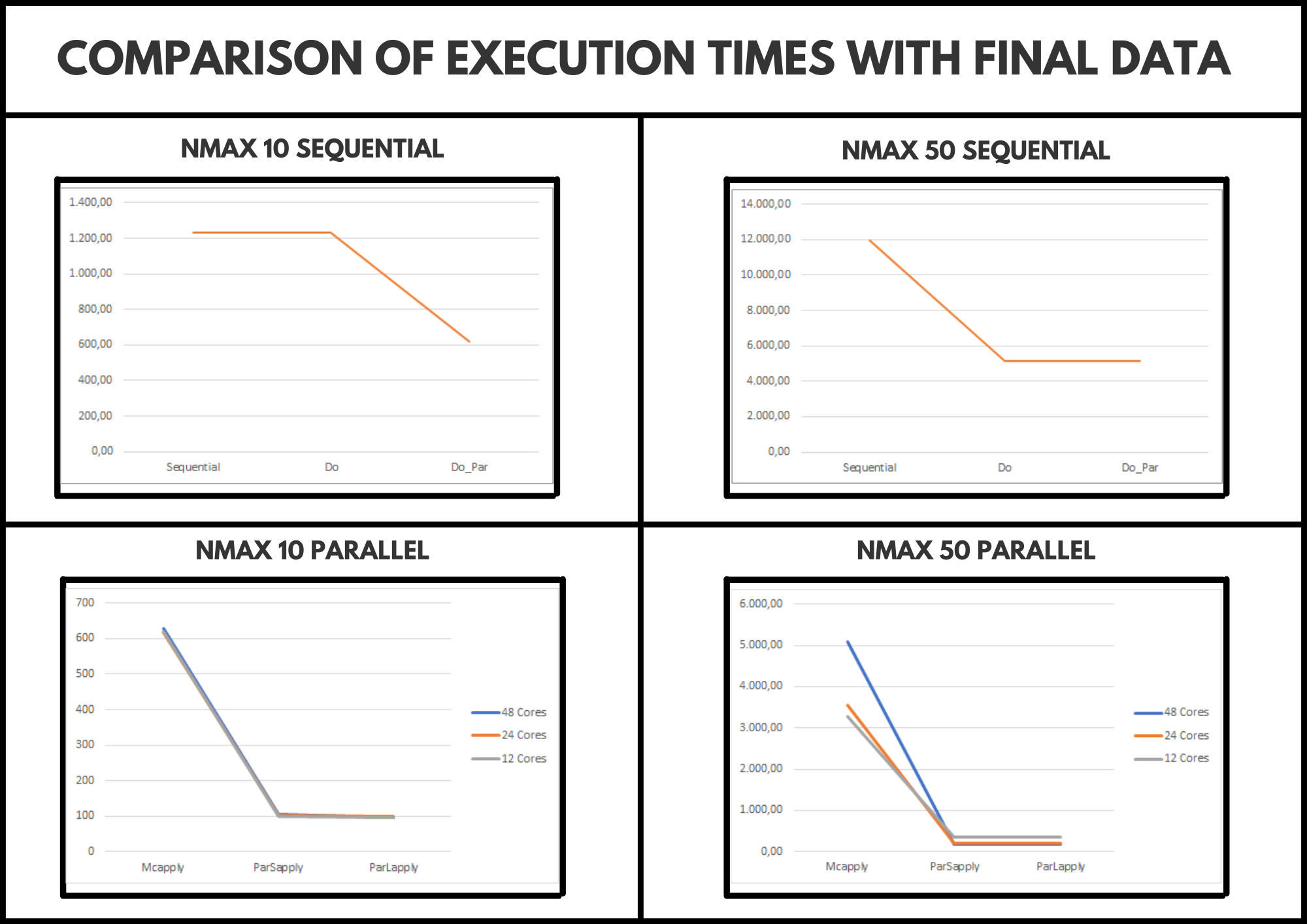
For the development of the comparison, the server provided by the research mentor has been used. By having 48 cores, the code has been executed using 48, 24 and 12 cores to obtain more complete results. It should also be noted that the code has been modified by adding a new variable called “Nmax”. This allows us to configure the size of the problem and, therefore, through logic, the smaller it is, we should obtain a shorter execution time.
After carrying out the comparison, we have detected that for a medium problem size (Nmax 10), the most optimal is to use 12 cores since they provide us with less execution time and we can leave the other 26 cores available for another execution, however, for a larger problem size (Nmax 50), we can see that using 48 cores is the most optimal option.
Finally, we can say that ParSappply obtains a shorter execution time, however, it should be noted that ParLapply has a higher time but quite similar, therefore, the most logical thing would be to use either of these two options.
These conclusions are supported under the image we can see below: