Supercomputing: a good resource for deep learning application
As much as neural networks keep exhibiting their importance, featuring in the success records of several research works. Building good performing neural networks models do not come by easily due to some factors like finding the most suitable parameters for the model training, large size of data and computational complexities of the models.
Today’s briefing will be about a generic overview of how to improve the performance of model training. As discussed in the previous post, a deep neural network has the ability to approximate any continuous function. It is brilliant at finding the best relationship between features to produce the best results. Although, highly multidimensional data or high number of parameters tends to affect the performance of the model. In addition, having a large or deep model can affect the performance of the model too because it requires a lot of memory due to intensive computation.
However, the advent of Graphics Processing Units (GPU) has come to unravel these caveats and makes it possible to conduct parallelization or distributed strategies for model training. GPUs process many pieces of data simultaneously which makes it useful for machine learning algorithms. Multi-GPUs demand communication among the processes and this is what brought about Message Passing Interface (MPI). MPI is a medium through which processes communicate. For instance, in point-to-point communication, two processors communicate directly between each other. While collective communication enables a single processor to communicate with several other processors.
There are several strategies to carry out parallelism but we are going to be talking about just data parallelization and model parallelization in this post. Data parallelization is basically the use of the same model for every thread but with different parts of the data. While model parallelism is an act of using the same data for every thread, but split the model among threads.
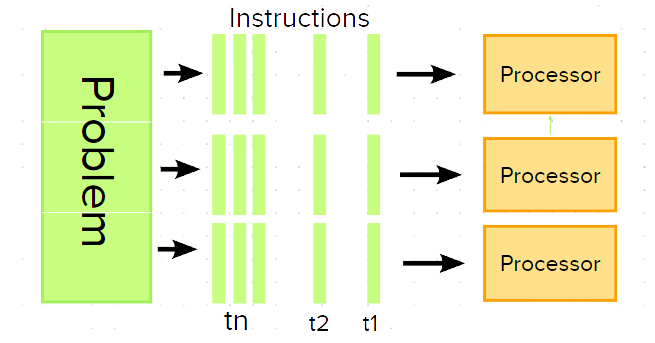
Lastly, these approaches have been good resources to build performant models of neural networks. Thanks for your time, but hope to see you again.
