The best of both worlds
Sometimes, rejecting unfeasible ideas early enough is a crucial step towards actually solving a problem. In my quest to speed up the ocean modeling framework Veros, I considered the option of restructuring the existing pure Python code in order to produce more efficient, automatically optimized code by Bohrium. However, that would require deep knowledge of the internals of a complex system like Bohrium and in practice, it is hard to identify such anti-patterns. Moreover, rewriting the most time-consuming parts in C or C++ would also potentially improve the overall performance but that choice would not be compatible with the goals of readability and usability the framework has set. A third, compromising solution had to be found.
Cython enables the developer to combine the productivity, expressiveness and mature ecosystem of Python with the bare-metal performance of C/C++. Static type declarations allow the compiler to produce more efficient C code, diverging from Python’s dynamic nature. In particular, low-level numerical loops in Python tend to be slow, and although NumPy operations can replace many of these cases, the best way to express many computations is through looping. Using Cython, these computational loops can have C performance. Finally, Cython allows Python to interface natively with existing C, C++ and Fortran code. Overall, it provides a productivity and runtime speedup with minimal amount of effort.
After adding explicit types, turning certain numerical operations into loops and disabling safety checks using compiler directives, I decided to exploit another Cython feature. Typed memoryviews allow efficient access to memory buffers, without any Python overhead. Indexing on memoryviews is automatically translated to a memory address. They can handle NumPy, C and Cython arrays.
But how can we take full advantage of the underlying cores and threads? Cython supports native parallelism via OpenMP. In a parallel loop, OpenMP starts a group (pool) of threads and distributes the work among them. Such a loop can only be used when the Global Interpreter Lock (GIL) is released. Luckily, the memoryview interface does not usually require the GIL. Thus, it is an ideal choice for indexing inside the parallel loop.
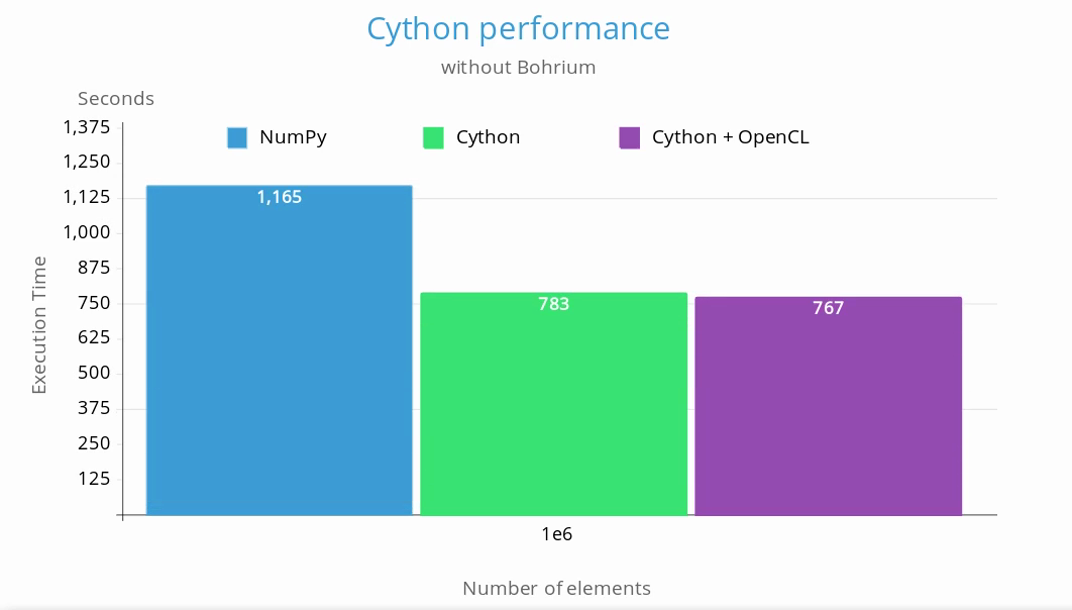
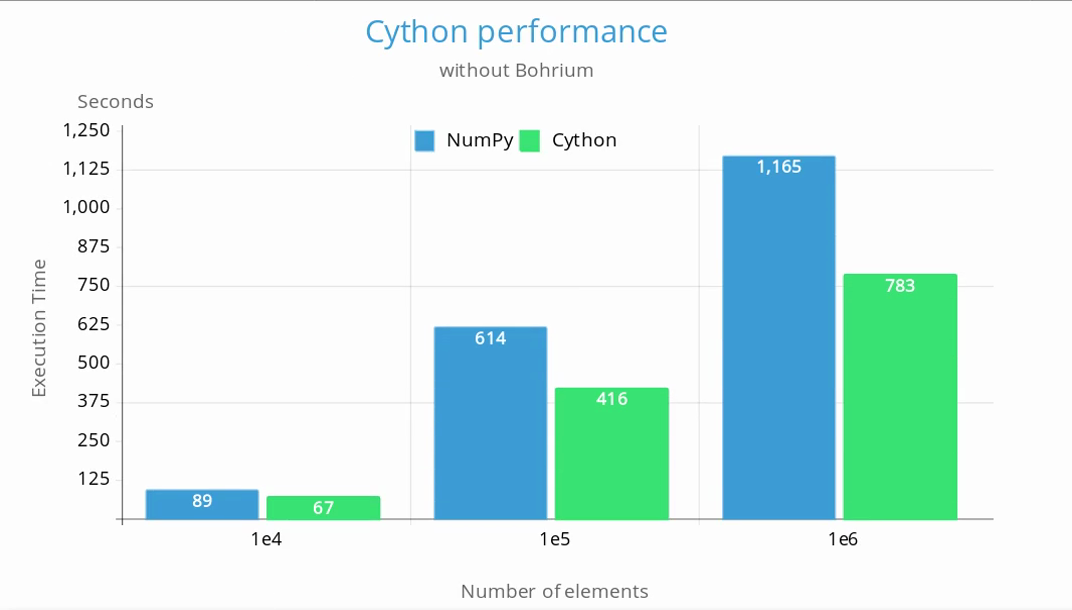
Because of its large overhead, Bohrium was not used in the benchmarks. Below is a chart comparing the execution time between the original NumPy version and the one with the critical parts implemented in Cython:
Even though not much time was left, I still wanted to attempt to port a section of the framework to run on the GPU. Veros solves a 2D Poisson equation using the Biconjugate Gradient Stabilized (BiCGSTAB) iterative method. This solver, along with other linear algebra operations are implemented in the ViennaCL library. ViennaCL is an open-source linear algebra library implemented in C++ and supports CUDA, OpenCL and OpenMP. In order to execute the solver on the GPU, I created a C++ method that uses the ViennaCL interface. Cython passes the input matrices to C++ where they are reconstructed and copied to the GPU. The solver runs on the GPU and the result vector is copied back to the host. Finally it is sent back to Cython without any copies. This procedure was implemented both for CUDA and OpenCL.
Here is the comparison between NumPy, Cython and Cython with the OpenCL solver:
Now that the programme is coming to its end, it is time to express my thoughts on the whole experience. This summer I made some awesome friends and worked as part of an amazing research group – I hope our paths will converge again in the future. I traveled more than any previous time and had the chance to explore many and different places. Of course, I had the opportunity to expand my knowledge and improve my programming skills. So if you are interested in computing, consider applying in the years to come, Summer of HPC is one of the best ways to spend your summer!
