A Matryoshka linear solver

As I described in my previous posts, solving a linear system in a lattice QCD applications can be a very long process. We really want to optimize this linear solver, so we can find some answers about matter in our world.
In HPC, every time we want to obtain better performance we have two ways:
- Use a different hardware (for example, using a more powerful supercomputer, or increase the number of processors)
- Use a different software (for example, using a more efficient method)
In this project we are aiming at exploiting both.
The hardware: what is a GPU? Why do we need GPUs?

This is a NVIDIA GPU: a small dimension but a big computational power.
GPUs were originally created for manipulating computer graphics and 3D images. They are everywhere: in your laptops, in embedded systems, in videogame consoles and in your mobile phone.
Since images are made of pixels and each pixel can be modified separately, GPUs have an intrinsic parallel structure: each GPU has hundreds of cores that can handle thousands of threads.
It did not take long for HPC scientists to start wondering about using GPUs parallelism not only for processing images, but for scientific computing as well; GPUs are now used as coprocessors, along with normal CPUs in scientific computations. And in my project, I am using GPUs to accelerate our linear solver.
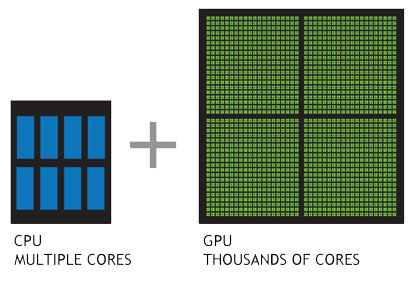
Differences between CPUs and GPUs (image taken from NVIDIA)
The software: what do Multigrid methods and Russian Matryoshkas dolls have in common?
Our physical world is continuous: it means that you can move smoothly in the space. But for computers bits a continuous world is impossible to handle.
How can we face it? A simple solution is to ‘draw’ a discrete grid in our continuous space. In this way you can use you computer to calculate, for example, the velocity of a particle at each point of the grid. You can see? You are actually solving a linear system in which velocities are the variables!
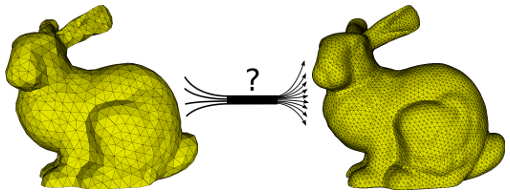
A discretized multigrid version of a bunny. Image has been taken from this article
If you want to know the trajectory of the particle very accurately, you would draw a very big grid with many points.
More points → more variables → bigger linear systems → much more time to solve them!
With multigrid methods we build two grids: one very big (the fine grid) and one small (the coarse grid). The small one is easier to solve, but the solution is not accurate enough for our problem. We take this solution and we ‘jump’ into the fine grid: then we use this approximate solution as a starting point for solving our problem in the fine grid.
Matryoshka Multigrid method
Of coarse, you can decide that your coarse grid is still too big and it is too difficult to solve it: no problem, because you can create another grid that is smaller, and then another one and then another one. At the end, you can have many grids of different sizes and you can jump from one to another (yes, like with Russian dolls called Matrioska Matryosha Matryoshka)
In practice, with a multigrid method you do the following:
1. You compute an approximate solution on the fine grid (this is only an approximation so it does not take long. This phase is called pre-smoothing)
2. You project your solution from the fine grid to the coarse one (this is the ‘jump’).
3. You solve the problem on the coarse grid, using the projected solution as a starting point.
4. You project everything back to the fine grid, and (optionally) you try to improve your solution a little bit (this is called post-smoothing)
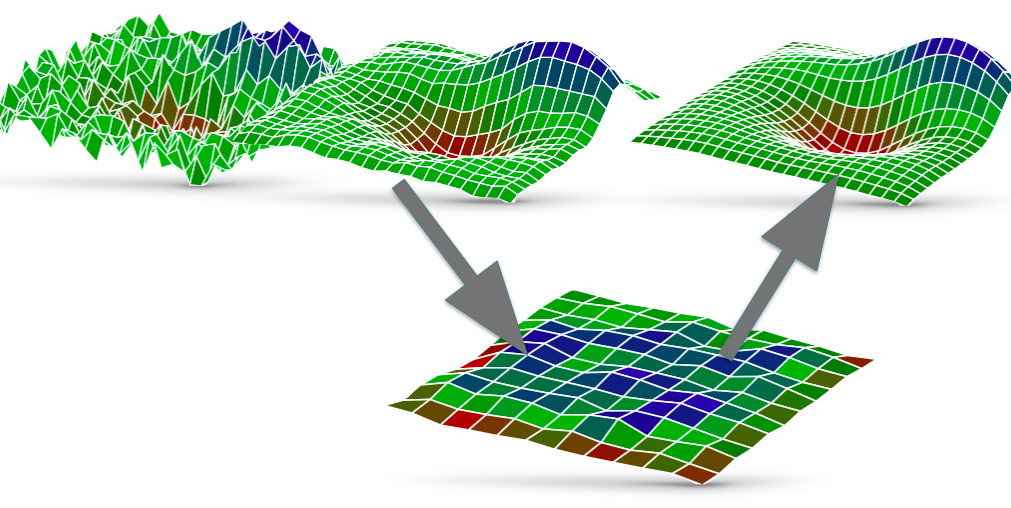
Multigrid in practice: smooth, project, solve and project back. Repeat until you are satisfied. Image taken from the university of Illinois website
Conclusions
So we have the hardware (GPUs) and the software (multigrid methods). Putting these two together, it seems that our challange is finally coming to an end! Will we achieve to boost lattice QCD performance? The Summer of HPC is almost finished, and we will soon have the answer…
