Beads beads beads

Let’s catch up with what my tasks have consisted in this far, one month into the SoHPC.
Since my very first day at STFC-Hartree, I was introduced to the DL_Meso simulation package, particularly to the Dissipative Particle Dynamics library, or DPD.
https://www.scd.stfc.ac.uk/Pages/DL_MESO.aspx
Briefly, this code allows simulating the physics of the mesoscale. Let’s assume that we are trying to perform an experiment with one or more fluid phases: a classical example could be a mixture of oil and water.

By mesoscale I mean the range of size between molecules (micro-scale) and droplets (macro-scale). The DL-Meso DPD code deploys a finite number of particles, or beads, whose dynamic will be simulated; as result, we will obtain information on our experiment accordingly to the size of our beads and to the simulation volume considered.
Clearly, as the number of beads increases, we have to move to more powerful computers. Moreover, the code can benefit from the usage of GP-GPU accelerators (General-Purpose computing on Graphics Processing Units) by means of CUDA C, therefore its possibilities are enormous in terms of running configurations.
The main task I am facing during the SoHPC ( https://summerofhpc.prace-ri.eu/author/davideg/) is to understand how the DL-Meso DPD code scales, or, in simpler words, how the time required to provide an experimental result is affected by the number of exploited resources.
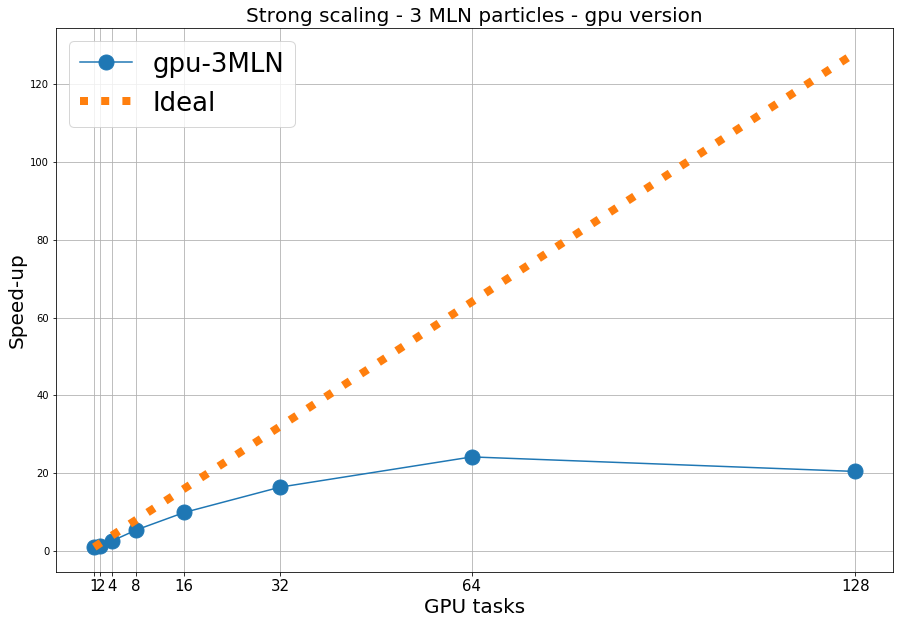
Ideal speed-up happens if, for doubled resources, we obtain half the execution time.
As you can see from the picture above, which represents the first obtained results, the difference between ideal speed-up and my data is of some importance. From this, we understand that the problem is not that simple, as many factors influence the performance of our code: above all Input/Output, number of simulated beads.
In conclusion, the exploration of the capabilities of the DL-Meso Code is keeping me busy during the SoHPC; furthermore, as I gain more confidence with the software and the supercomputer (We are talking about Piz Daint, the greatest supercomputer in Europe, which allows me to use up to 5704 CPU-GPU nodes: https://www.cscs.ch/computers/piz-daint/. Some caution is mandatory, especially when launching jobs with 2000 of them!), some extensions will be performed, in order to increase the possible scaling experiments or verify new features.
Mechanical engineering graduate student, always ready for new experiences. Currently, in Warrington, UK, working on Mesoscale simulations on GPGPU architectures.
