
If you want to know the story from the beginning, I recommend checking out previous entry if you haven’t already that is about the project I’m working on this summer and opportunities you can get if you opt to apply for the programme.
This chapter aims to introduce an emerging approach of managing data that has the potential of breaking restrictions set by traditional hardware architectures and to show you how it is used and its performance in a real world.
What is a Non-Volatile Memory?
As you are probably familiar with, modern computers use different types of storage units to achieve different kinds of tasks. Mainly, there are two needs every processing unit requires:
- Speed and
- Persistence
But as of now, each storage device is only specialized in one of the two:
- Registers – the fastest, but there are only few of them in each processing element and they are volatile
- Caches – next in terms of speed, but also lack in capacity and persistence
- DRAMs – last in “speed race” of non-persistent devices, but have the greatest capacity of them all
- SSDs and HDDs – the devices which allows data to be saved independent of electrical power but also with speed not comparable to other types of volatile storage

Source: Intel
Whole situation with storage is changing really slow so far as it follows a trend of only enhancing hardware capabilities without any advancement in terms of new design. But that seems not to be the case any more since there is a new storage device that promises the speed comparable to current DRAMs and also ability to persist data only found in big-sized devices such as SSDs and HDDs.
This type of storage is called Non-Volatile Memory – nothing special in the name, but with the potential to change current ways of managing and saving the data especially important in high performance computing where I/O operations usually are application’s bottleneck. Next, we’ll dive deeper and learn about concrete hardware I’m using on my project as well as gain a first look at the device in action.
Storage Performance
After finishing the training week, I started working on this summer’s project – re-writing existing Charm++ fault tolerance system that uses online check-pointing to take advantage of newest non-volatile memory technology.
Courtesy of EPCC, my teammate Roberto and I have a chance to use their new cluster NextGenIO with nodes equipped with Intel’s Optane persistent memory modules.

Source: Intel
Memory provides two distinct modes in which it can be used:
- Memory Mode – module is used as a volatile memory with big capacity where DRAM units become last level cache; good for applications that use huge chunks of memory, but the memory is still slower than DRAM which can have impact on performance of small-memory programs
- App Direct Mode – module is used as a persistent unit and is mounted to regular file system accessible using regular file interfaces within the application; good for redirecting temporary program states from slow disk storage to much faster persistent memory and also enhance applications heavily dependent on I/O operations
In our case, we are using the memory in App Direct mode cause we need to persist the data each time we do the checkpoint. The first idea we’ve tried was to change the location where checkpoints are saved to now mounted persistent memory in our file system. Without too much trouble, we immediately managed to achieve an expected speedup.

After accessing the memory using standard file I/O interface (also called fsdax – file system direct access), we’ve enhanced previous solution by using development kit (a.k.a. PMDK) for directly accessing the device skipping overhead caused by OS file handling i.e. devdax.
Pmem library gives the programmer API similar to existing C interfaces for handling memory mapped files, but with potential gains in performance by directly accessing non-volatile memory which we were able to confirm after testing.

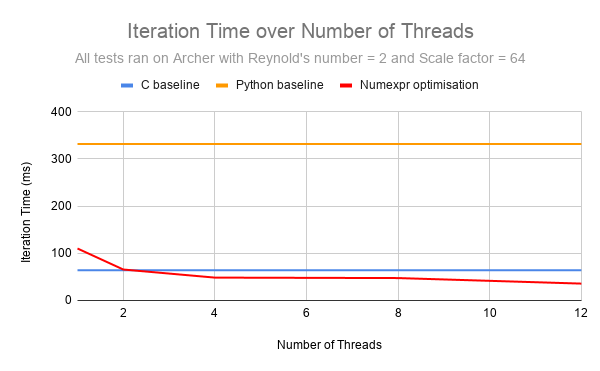
Best way of looking at the results by comparing gained speed-ups side by side. Worth noting is that these results are experimental and not confirmed with larger scaled tests, but we don’t expect to much of change in relative gains we managed to get so far.

Next goal is to make whole system fully transactional which will definitely impact the overall execution of application, but with help of this new memory, maybe it’ll be feasible to get acceptable performance with full fault tolerance capability! Stay tuned to find out!


































{kind=link}