Check-pointing finished

If you are interested in knowing the whole story, I recommend checking out previous entries, if you haven’t already, that are about the project I was working on, the progress I’ve made during the summer and opportunities you can get if you opt to apply for the programme.
We’ve reached the end of the road, or at least this one. It was quite a summer for me and I would like to tell you about the impressions I’ve gathered during the summer and wrap up the story about the project in which I’ve participated.
Benchmarks
After we managed to finish the first phase and performed initial testing, which was discussed on the previous post, we’ve put our work to a real challenge – scaling!
Evaluation has been done by performing already present Jacobi application which task is to determine the solutions of a strictly diagonally dominant system of linear equations. This method is well-known and broadly used in the field of high performance computing. The program it self was not what was interesting, but the fact it used online Checkpoint and Restart (C/R) system for fault tolerance while performing the calculations is why it was a perfect fit for our needs.
We’ve performed test multiple times each time varying the run configuration. It consists of two main parameters:
- Number of Chares
- Number of Cores and Nodes
By changing input array size and block size ratio, the application automatically adjusts by dividing the calculation into respective Chares objects, which directly impacts the size of checkpoint that is saved each time. Also, varying number of processing elements and ordering them on different nodes affects the fault tolerance system cause it fundamentally saves the application’s state by saving the state of every Chare and with more cores comes more of them.
To fully evaluate the performance gained, we’ve performed checkpointing in different modes, both previously present and newly added, for each configuration. Modes used for evaluation are:
- Memory mode (built-in) – uses DRAM for storing checkpoints
- FSDAX – uses Persistent Memory by accessing it via regular file I/O API
- PMDK – uses Persistent Memory by accessing it directly via Persistent Memory Developer Kit (libpmem library)
- Disk mode (built-in) – uses disk for storing checkpoints; it exploits memory caching by default (which doesn’t provide full persistency)
- Disk mode w/ O_DIRECT – similar to previous, but explicitly requires operations to be performed directly to disk and not using memory as a cache
Results obtained by our evaluation can be best understood by looking at the charts bellow:
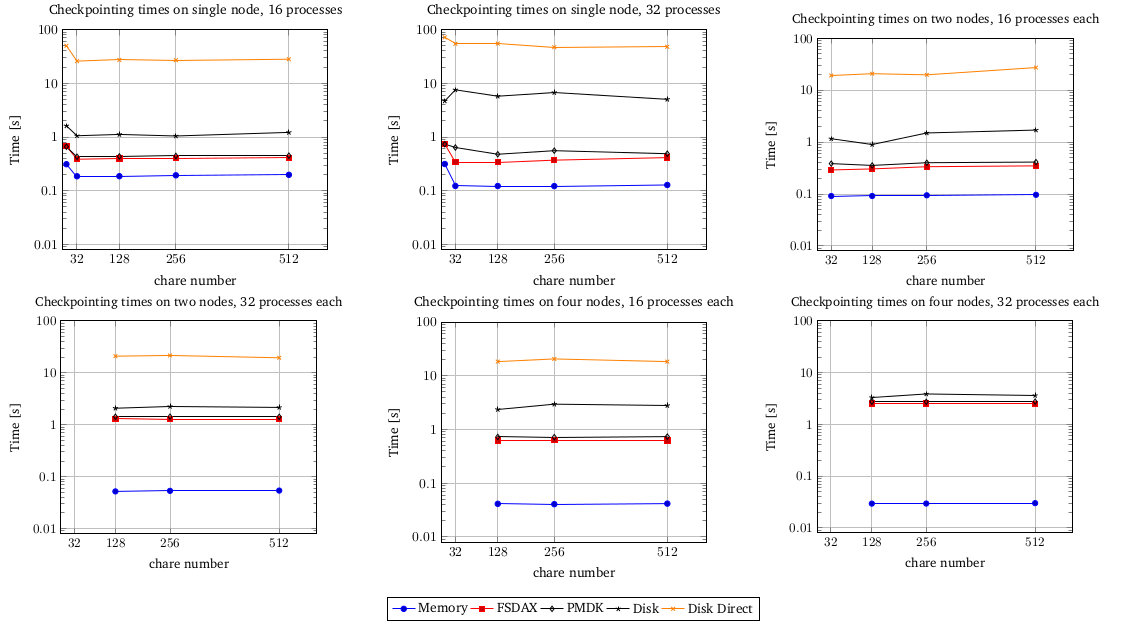
As you can see, every mode behaves pretty much the same with configuration changes, where the Memory mode is always the fastest (as expected), after it coming FSDAX and PMDK approches with times comparable with previous, then the Disk mode which profits from memory caching and shows times close to persistent memory and at last Disk w/ O_DIRECT being hugely behind all the previous modes.
We can conclude that:
- Both persistent memory approaches give great gain over regular disk and are similar in terms of the performance
- Disk w/ memory caching also shows good performance, but is not fully reliable cause intermediate cached data that isn’t yet flushed to the disk can be lost during the failure which makes the content on disk obsolete
- Disk w/ O_DIRECT solves previous data consistency problem, but proves to be really slow and thus makes overall application inefficient (especially when checkpointing frequently)
Future
Speed-ups obtained with persistent memory proved our initial desire – to achieve persistent checkpointing with major performance improvement. With that, my teammate and I tried to tackle our ultimate goal – to make fault tolerance transactional.
To make the system completely transactional, it is needed to comply with a set of constraints named ACID which stands for:

Source: Yalantis
These strict constraints aren’t usually used outside of database field, but with today’s trend where HPC systems are becoming larger and larger, probability of failure occurring during the execution must now be accounted when designing large parallel applications.
Fundamentally, to make Charm++ checkpointing ACID compliant, it is required to do two things:
- Send messages only after the entry method is successfully executed – which we were able to do for basic message sending (excluding array broadcasts)
- Make checkpointing asynchronous – this point was hard to implement for a short period of time cause Charm’s system for checkpointing is designed to be used synchronously
Final impressions
Although we haven’t reached our ideal goal, my team and I are really content with what we’ve managed to achieve during these last two months. We’ve proven the expectations promised by the storage innovation we had a chance to work with and hopefully showed you that this memory has a real potential and can be useful in the field of HPC especially for enhancing current fault tolerance systems.
We’ve also summarized the whole project in a short video which you can check out bellow:
I’m grateful for having an opportunity to work on this cool research project and I must say that being part of the team and not working alone exceptionally this year turned out to be probably the best part of the whole experience.
If you got interested in this kind of research internship, do not hesitate to apply for next year’s Summer of HPC and be a part of this amazing programme! Of course, if you have any other concerns, I’m more than available to help you with those, just contact me via LinkedIn or leave a comment bellow.
Thanks again for being with me this summer and I hope we’ll be seeing each other soon on some new adventure!
