MPI Makes Machines Learn Faster!

As I mentioned previously, the main goal of our project is to improve the performance of a ‘decision tree’ algorithm using High Performance Computing (HPC) parallelization tools such as MPI and GASPI. In this post I will try to explain how MPI can improve the learning speed of decision tree.
Parallelization of Decision Tree
Decision tree is a well-known supervised ML algorithm. I’m sure that many of you at least heard about it, but if I try to explain it in one sentence, I can say that it is a binary tree that predictions are made from the roots to the leaves. Even though it can be used for both regression and classification, in this study we focused on classification problem. Our decision tree is relatively simple; it is a recursive algorithm and contains only one hyper-parameter, maximum depth, controlling the stoping criterion ( there are others but we didn’t cover them for simplicity).
Algorithm splits the data sets to nodes according to ‘selected’ treshold values of ‘selected’ features in the data set. Each node is assigned with a GINI index which is a simple mathematical expression describing the purity of the node. The aim is to select optimal feature and threshold couples minimizing the GINI index for each split. The algorithm stops when the maximum depth is reached or when all the inputs are classified.
Our parallelization strategy is distributing features among different computation units. In this approach, each processor core is responsible for one or more feature sets to survey all possible splits and compute corresponding Gini indexes to evaluate them. Therefore, in every recursion, each core finds a best feature and threshold couple minimizing the Gini index for their portion of the data. After this, all the best feature and threshold couples are gathered together at the master core 0. The master core compares them according to their Gini indexes and broadcast the best result to all the other processors.
Results
As we can expect, the results show that the higher the number of cores, the higher the speed-up rates. Total computation time is decreasing with increasing number of cores. Here, the computation time corresponds to run time of learning (data fitting) process of the algorithm.

It is also seen that the rate of change is also decreasing with increasing number of cores. This is the result of inevitable communication overhead. In an ideal world, workers can do their job independently, but in real world, synchronization mostly is a must. There is no chance to escape from communication overhead required by synchronization in MPI parallelism. So in reality, speed up is always less than the increase of the number of workers.
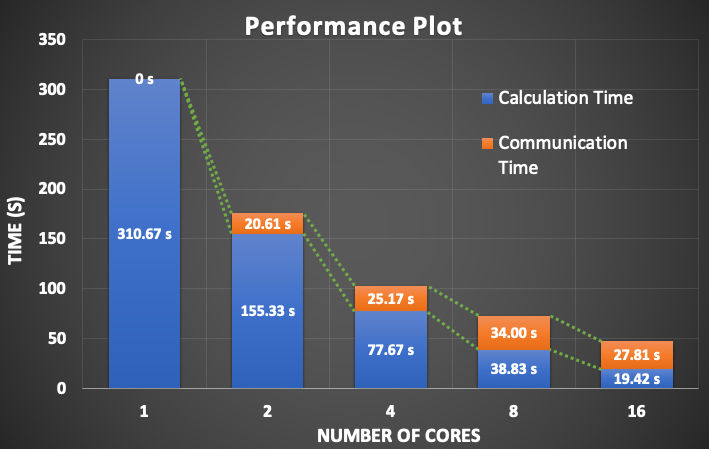
The figure abouve shows the portions of the total computation time dedicated to calculation and communication. As it is seen that time spending for communication is increasing with increasing number of cores. Higher number of cores means that higher number of send and receive commands and for each command, cores should wait for each other. On the other hand, chunks of data which is transferred is getting smaller, and this makes faster the data transfer. Therefore, the increase in the communication time is not linearly increasing.
As I told you that MPI makes machines learn faster!
