Taking advantage of vast hardware resources

Supercomputers are able to perform a huge number of operations per second. But having a powerful machine is not the only ingredient for short execution times – the software has to be optimized and has to exploit all available resources.
Our project focuses on the optimization of the computation of the exponential of a general complex matrix in an HPC environment using the algorithms that have been discussed previously. We are working on Jean Zay, a national supercomputer of France which is based at IDRIS. During this summer several extensions have been installed and now its accumulated peak performance is at 28 Petaflops.
These are 28 000 000 000 000 000 operations in one second! Pretty amazing, isn’t it?
Jean Zay has CPU as well as GPU nodes – in the case of linear algebra for dense matrices, it is expected that the performance on GPUs is better than on CPUs. As a consequence, we started with an implementation of the matrix exponentiation on a CPU and benchmarked it on one core and on 40 cores. Both algorithms – Taylor series and diagonalization – showed a speedup comparing the execution on one core and on several cores for different matrix dimensions. The next step was moving to the GPU.
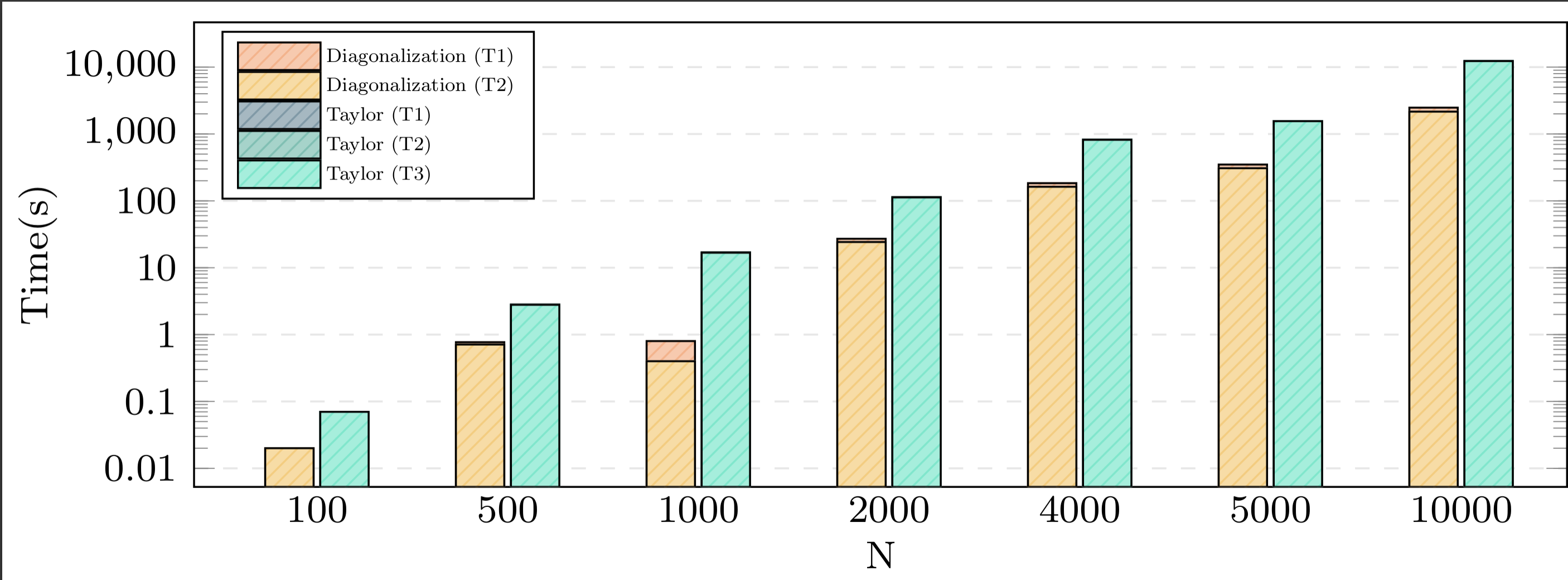
Execution times on one core 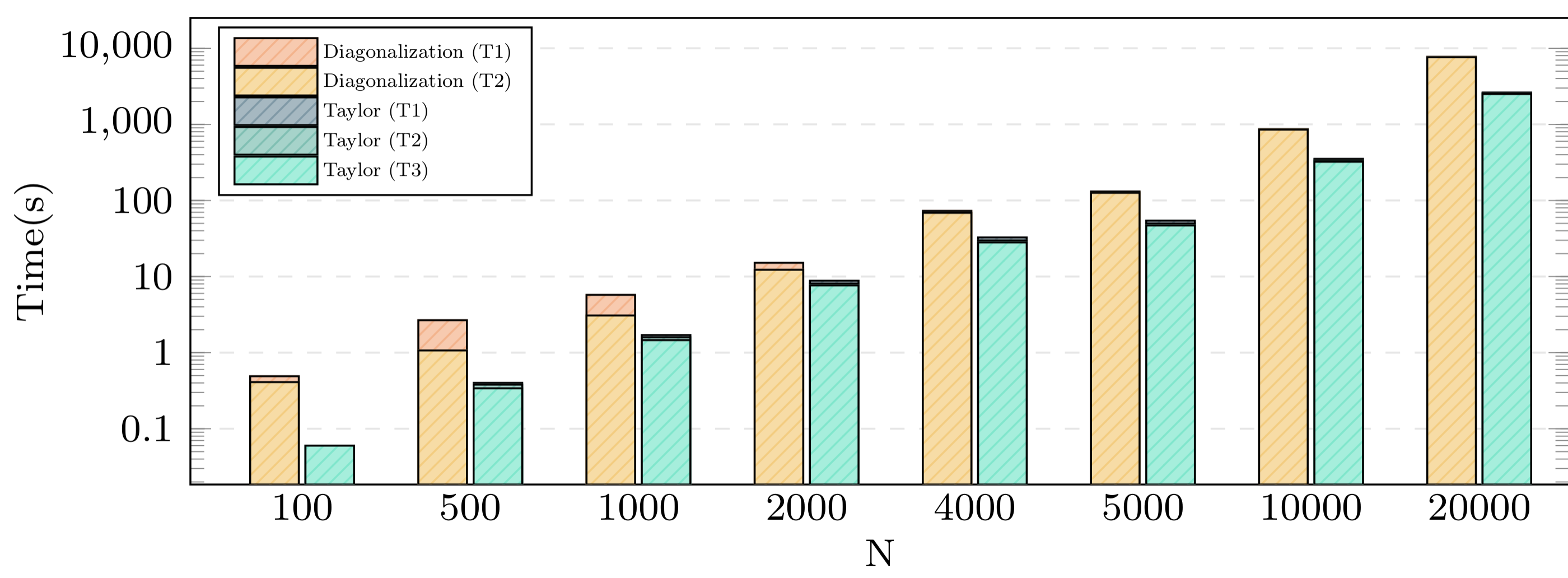
Execution times on 40 cores
As expected, the execution time of the version for the GPU showed a significant speedup compared to the implementation on a CPU. Especially the implementation using Taylor series performed very well but diagonalization for large matrices is almost as fast as using Taylor series.
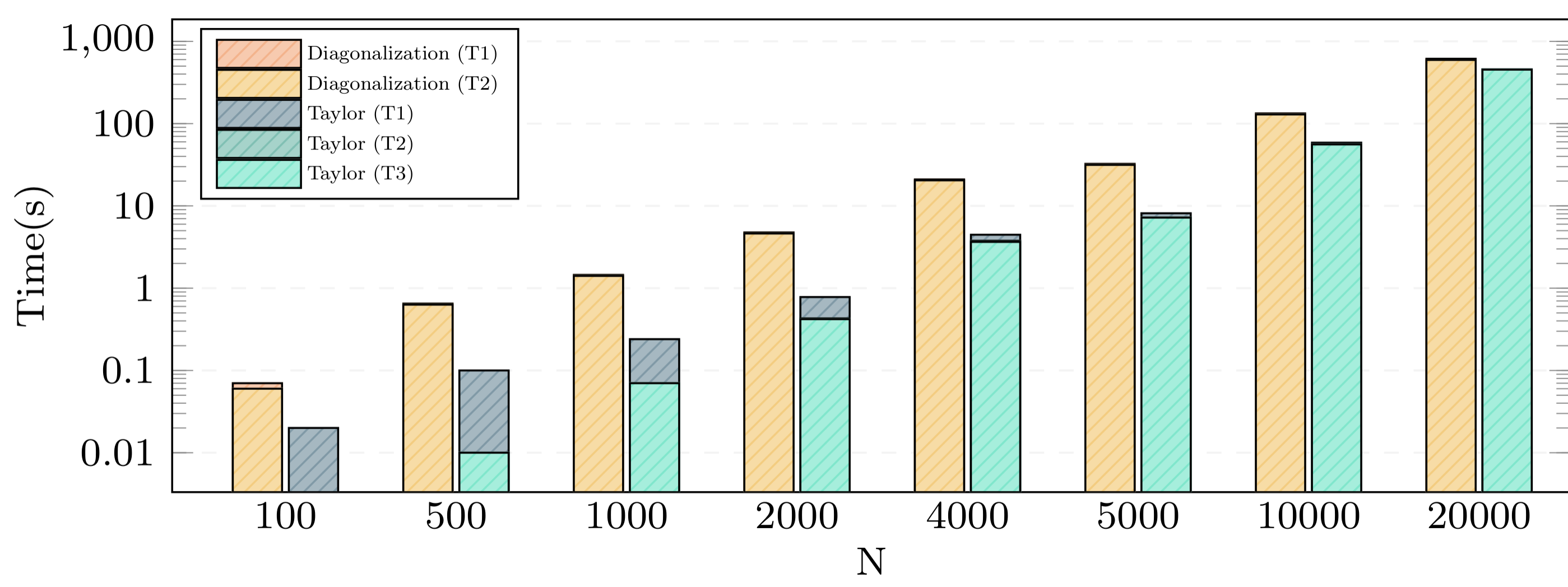
Execution times on GPU 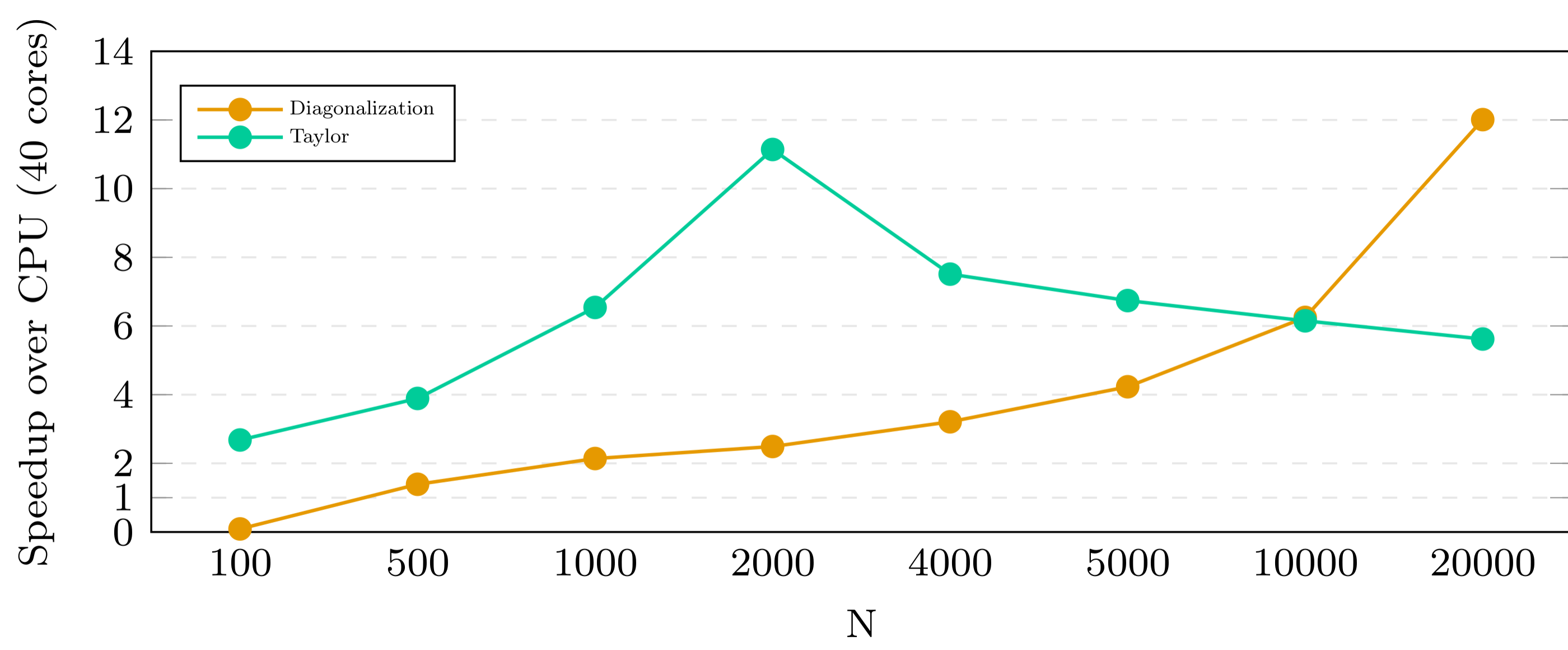
Speedup of GPU version compared to CPU version on 40 cores
Conclusion
Matrix exponentiation is very well suited to be performed on a GPU and we obtained efficient programs to compute the exponential of a general complex matrix. The speedup of our different versions is very satisfying and the final result can be used in the future.
