Artificial Brains for enhancing Crowd Simulations?!

Hi all,

My girlfriend was visiting me in Barcelona, so we figured we had to go to the beach!
In my previous post I introduced myself and the SoHPC programme. Now it’s time for my project.
Why Crowd Simulation?
Throughout history, humankind has had a clear preference for grouping together in larger and larger groups. On the global scale, 54 per cent of the world’s population are living in urban areas as of 2014. In 1950, this figure was 30 per cent, and in 2050 it is projected to be 66 per cent. [1]
Planning ahead for this massive increase in urban population will be demanding, and having an accurate simulation to test your city’s new infrastructure might save lives. We can, using both modelling and real data, see how people react to various external stimuli such as a catastrophe or a change in the road.
What words are those?
Monte Carlo and Deep Learning Methods for Enhancing Crowd Simulation
Yep, that’s my project title. Loads of fancy, technical words! All this media coverage of artificial intelligence and how it will take over the world is probably not helping with the confusion of the “man in the street”, how can a machine alone do my work?! Before I start talking about what I’m doing, I’ll try to quickly explain what Monte Carlo and Deep Learning methods are.
Monte Carlo Methods
Monte Carlo methods refer to methods of obtaining numerical results in which we randomly sample a small part of the whole space we would otherwise need to compute every point of. A good example is computing the total volume of particles in a box which could fit up to N³ particles. A normal way of computing this involves checking every single location, whereas a Monte Carlo algorithm might only check on the order of N locations, and then extrapolate the result. There are obvious limitations to this, but it works surprisingly well in the real world!
Artificial Intelligence, Machine Learning, Neural Networks, Deep Learning, Reinforcement Learning… HELP!?!?!?
Artificial Intelligence (AI) can be defined as the study of intelligent agents; a device that perceives its environment and takes actions that maximize its chance of success at some goal. [3]
Historically, we can divide approaches to AI into groups of thinking or acting humanly or rationally. One way of determining whether a machine has reached human level intelligence is the Turing test. As laid out in Russell and Norvig, a machine needs to possess several capabilities in order to be able to pass the Turing test. Amongst those are understanding natural languages, storing information and using this information to reason, and to be able to learn and adapt to new situations.
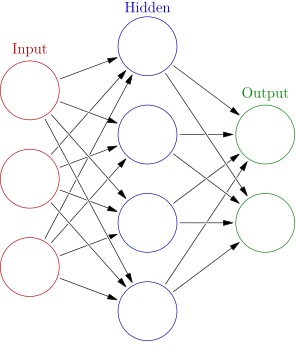
An Artificial Neural Network. This specific one can for instance learn the XOR (exclusive or) operation.
By Glosser.ca – Own work, BY-SA 3.0, Link
This last ability is what we often call Machine Learning (ML) – learning something without being told explicitly what to do in each case. There are many approaches to this; the one we will talk about is Neural Networks (NN). The basic idea is to model the structure of the brain, and also mimic how we humans learn. We split the task into several smaller tasks and then combine all the small parts in the end.
As explained in the Deep Learning book [3], we try to enable the computers to learn from previous experiences and understand the world in terms of a hierarchy of concepts. Each concept is defined using those concepts further down in the hierarchy. This hierarchy of concepts model allows the computer to learn complicated concepts by building them out of simpler ones.
This hierarchical model, when laid out in graph form such as in the picture on the right, is what has inspired the name Deep Learning. Deep Learning is when there are a large number of
hidden layers.
A visualisation of a Biological Neural Network, on which these artificial neural networks are based.
I feel it’s worth mentioning that most of the fantastic progress seen recently is in this field of AI. And that it is doubtful that this transfers directly to so called general AI due to the very specialised training required. However, Machine Learning will change what people spend time on that is for sure. Certain tasks are very well suited for this specific approach and I suspect we will soon see it commercialised.
A last thing I should explain is the term Reinforcement Learning (RL). It’s not often mentioned in media, but it is one of the most successful approaches, albeit limited to few domains, such as games. The basic idea is that we mimic how humans and animals are trained. If the agent does something good, say, doesn’t crash, it gets a reward. If it does something bad, e.g. crashes or breaks a rule, it gets punished. There are many approaches to solve this, they all centre around giving the machine a function which assigns a predicted score for every action in a state. [4]
What am I doing?
My project is mainly algorithmic in nature. I try to come up with the underlying rules each individual in the crowd must follow. The main ones are not crashing, leaving the area and going towards any goal you’ve been given. A secondary goal is coming up with a nice visualisation. This is mostly already done, but there will likely be a large amount of work in transferring the algorithm.

Illustration of a Markov Decision Process with three states (green circles) and two actions (orange circles), with two rewards (orange arrows). A POMDP is when some of this information is not given.
By waldoalvarez – Own work, CC BY-SA 4.0, Link
We will use a form of Monte Carlo method for solving a so called partially observable Markov decision process (POMDP) which we will use for navigating people towards a goal.
For avoiding collisions, we will combine deep learning with reinforcement learning, similar to what Google-owned Deep Mind did with the deep Q-network for playing Atari games, although our network will be much more shallow and far less complicated.
A last thing we hope to try, is using another branch of machine learning called supervised learning to instruct the agents on various aspects – such as some city paths are more likely to be taken. This can also be used to say that this road, which normally is the best option, at the time we want to simulate is in fact heavily congested and should be avoided.
The crowd simulations themselves are quite complicated creatures, so to develop the algorithms in the first instance, my primary weapon is pen and paper. After I have derived the idea, I implement it in the Python programming language, using a physics simulator called PyMunk and a game engine called PyGame. The biggest advantage of using Python is in fact Keras, a so called API for Neural Networks. It allows me to code my neural net in just a few seconds. Combined, these allow me to quickly test my ideas in practice.

Status of project as I was leaving the office Friday 21st of July. The green dot is the one I’m training and the blue dots are stationary obstacles we try to navigate around. The background shows training data left and right, and in the background is an algorithm I’m trying to see if we can adopt. The algorithm was proposed in the paper Deep Successor Reinforcement Learning as implemented for a self driving truck in this Euro Truck Simulator 2 project.
[1] – UN World Urbanization Prospects 2014 https://esa.un.org/unpd/wup/Publications/Files/WUP2014-Highlights.pdf
[2] – Artificial Intelligence – A modern approach 3rd edition; Russell & Norvig, Pearson 2010.
[3] – Deep Learning Book; Goodfellow, Bengio and Courville; MIT Press 2016 http://www.deeplearningbook.org/
[4] – Reinforcement Learning: An Introduction; Sutton & Barto; Still in draft http://incompleteideas.net/sutton/book/bookdraft2017june19.pdf
The Biological Neural Network image comes from
http://legacy.iaacblog.com/maa2013-2014-advanced-architecture-concepts/files/2013/11/neuron-network12.jpg

[…] of algorithms. Business hasn’t been too good lately, mostly because of all these new competing faces on the scene and because libraries like OpenCL make it too easy to write parallel code for […]