All good things, unfortunately, come to an end!

Hello again, and welcome to my last blog post. Today as I write this post, the beautiful journey “Summer of HPC 2021” is about to end. The video presentations of all the teams were fantastic, and it seemed that we all loved what we did and had a good time. Through all this experience, I met new people, I learned new things, and above all, I had a creative summer that will be unforgettable for the rest of my life!
Before closing this article I would first like to give a brief overview of the timeline of our project. Despite the difficulties we faced, we managed to cope and carry out the problem that had been assigned to us. We have both worked hard and we hope our result will benefit the scientific community.
Profiling
The first thing to do when it comes to optimizing an application is to see how much time is spent. Using the VTUNE tool we found that the most time-consuming function was MatSOR which in turn calls the function KSPSolve. This function is responsible for solving a linear equation. So what we wanted to do was transfer these time-consuming operations to the GPU.
From CPU to GPU using PETSc
By reading the documentation of the PETSc library but also seeing various slides from training events of the specific library, we were able to identify how we could transfer the required operations of vectors and tables to the GPU. The library does not offer any correspondence between CPU functions and GPU functions, but all that needs to be done is to define the above with a special CUDA type.
For example, if we have a vector V and we want this to be defined on the GOU and not on the CPU, we should simply declare it by calling the VecSetType (V, VECCUDA) function. For an array M, the corresponding function is MatSetType (M, MATAIJCUSPARSE). Everything that has to do with the transfer of data between the different GPUs or between CPU and GPU is done by the library so we did not deal with this part. The difficulty we encountered at this point is that the CPU version of the code used a preconditioner function with the multigrid method. This function, however, did not have direct support for GPUs so we could not use it. Testing all the preconditioner functions with GPU support we came up with the default which was the Incomplete LU which had the best performance.
Yes, but is it correct?
When making a code change the first thing we need to make sure before taking measurements or continuing on further optimizations is to make sure our result is correct. What we wanted to make sure of at this stage of implementation was that we were not altering the original CPU output. We visualized the outputs of both implementations, the initial one and our own using ParaView, and checked the accuracy of our result. The two outputs were identical so we were ready to continue to the next stage.
Performance comparison
So, through a series of experiments, we now wanted to measure the performance of our implementation and compare its performance, changing various parameters such as the number of nodes, the number of graphics cards, and the number of MPI processes. One observation we made is that application performance on both the CPU and the GPU depends mainly on the number of MPI processes. Something that does not affect performance is the resource topology i.e. if the GPUs are all in one or separated in many nodes.
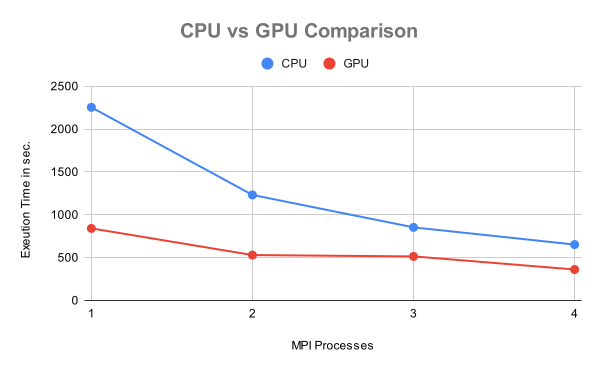
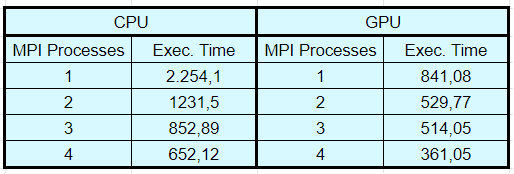
Our effort seems to outperform CPU implementation in 1, 2, 3, and 4 MPI processes, which is satisfactory and encouraging. If you liked our project and you were interested in our work, you can watch our video presentation in which we present the results of our research in detail.
Our Video Presentation
I would like to thank my partner for our cooperation, the mentor for the directions and instructions he gave us, and PRACE for giving us this opportunity to have such an experience.
