Bye-Bye Summer of HPC

Hello everyone again,
Today I come to tell you everything we’ve achieved during these two months with HPC! It is good news and I am going to tell it happily but at the same time very sad, the final week has come and we didn’t want it to come, all principles have an end and, of course, all endings are just the beginning of something bigger, and this is what has happened here.
New Family
At the beginning of summer, when it was announced that SoHPC2020 would go online because of COVID-19, it was bad news that would take the fun out of this great international internship. However, when you face a problem you simply get stronger. And that is why these two months have served to grow as people (#Stay at home), as students (#openACC, #HPC) and as researchers (#Julich, #Physics).
This has been the beginning of a new more virtual life that has also allowed me to meet many interesting people all over Europe, my classmate Anssi, my friend Jesús, my mentors Johann and Stefan,… with whom we share a passion, Computers! Thank you all!
GPU rules!
The positive side has been the amazing results we’ve obtained! To remember, in my previous posts (Cold start and Don’t stop me now!) you can inform in detail what is the work that I’ve developed during these months, which in short, was the export of an HMC code on graphene nanotubes from CPU to GPU using openACC library.
The hybrid method of Monte Carlo (HMC) with which we’ve been working, internally resolves dispersed linear systems calling two algorithms CG_single and FGMRES, developed by my colleagues at JSC. As a result of these systems presents the execution of a great number of instructions, we thought that it could be a highly parallelizable element.
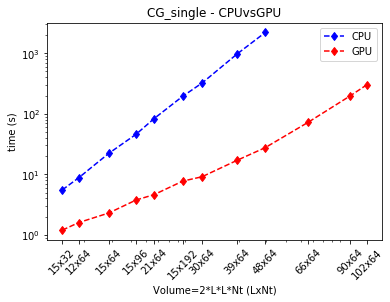
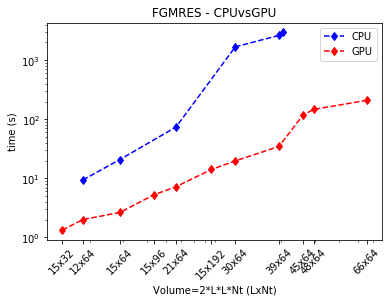
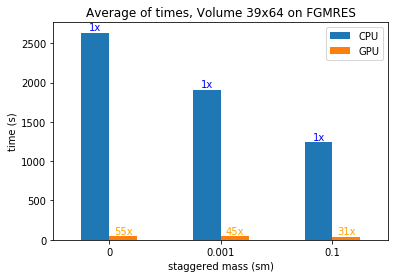
To show the improvement in performance and the importance of doing it well, we obtain in both solvers when we use GPU in their execution we’ve run two experiments for each solver. In the first one, we move the total size of the array, parameterized by the hexagonal lattice volume of the graphene, LxL with Nt timesteps. In these two plots, we can see the execution time required for the solvers CG_single and FGMRES, respectively.
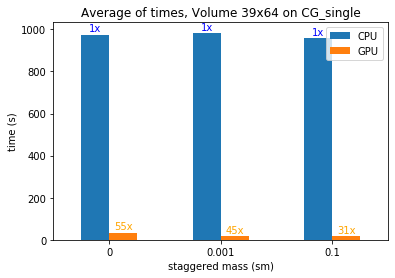
In a second experiment, we leave the volume fixed and change the staggered mass (ms), another parameter that intervenes in the creation of the matrix A, in the next two figures we can evaluate the Speedup that we get.
Future works
For some future projects on GPU execution it would be very interesting to implement a version with CUDA and analyze what further improvements can be obtained.

