Moving plasma particles simulations to GPU

Hello all! Here I am another day in a new blog entry. Today I will be giving some details about the simulations that we are doing in project 2019 and a brief description on our work.
If you do not know who I am or you want to read my introduction again, I leave a link here.
Why plasma kinetics?
Imagine you have 24 000 million euros (hopefully) and you want to invest them. After doing some research, you find out that you can build a nuclear fusion reactor called Tokamak which might be the best energy resource.
But you know that nuclear fusion is still in development and no one has achieved a stable and efficient reactor yet. The main issue that comes up with these reactors is the instability of the plasma (which is the energy resource of the core). And here is where plasma simulations take place. Obviously, you would not want to build a machine that may not work. Plasma simulations (in this case) give us the opportunity to track the plasma properties and be aware of its behavior, so the reactor’s structure can be adapted.
How are plasma simulations performed?
There are many kinds of physics models to describe plasma. In our case, and the most widely used model, is called Particle In Cell (PIC) code. These codes simulate each of the particles of the plasma. It updates each particle’s position, calculates the electric fields and many other features at each time step.
We want PIC codes to be the most accurate. To do so, they simulate up to 10 000 000 000 particles (10^10) and calculate electric and magnetic fields in thousands or more spatial points. So, by increasing the number of particles and grid points, our simulation will be more accurate.
HPC simulations
To add new plasma features and increase accuracy, more and more computational power is needed, but this is a limited resource. Here is where my work starts.
Most of the PIC codes run only on CPUs which limits the performance of the code because the computing time scales with the number of particles. To minimize these restrictions, the simulations can be carried out by GPUs.
Simulations in GPUs take the advantage of the large number of threads of this kind of device. Each thread performs one set of calculations independently from the others. For example, a standard (user distributed) CPU has between 6 to 16 threads while a GPU has 10000 or more threads. The key point to move a process to GPUs is to think of a way of make the computations independent. Also, you have to take into account data transfers between CPU and GPU.
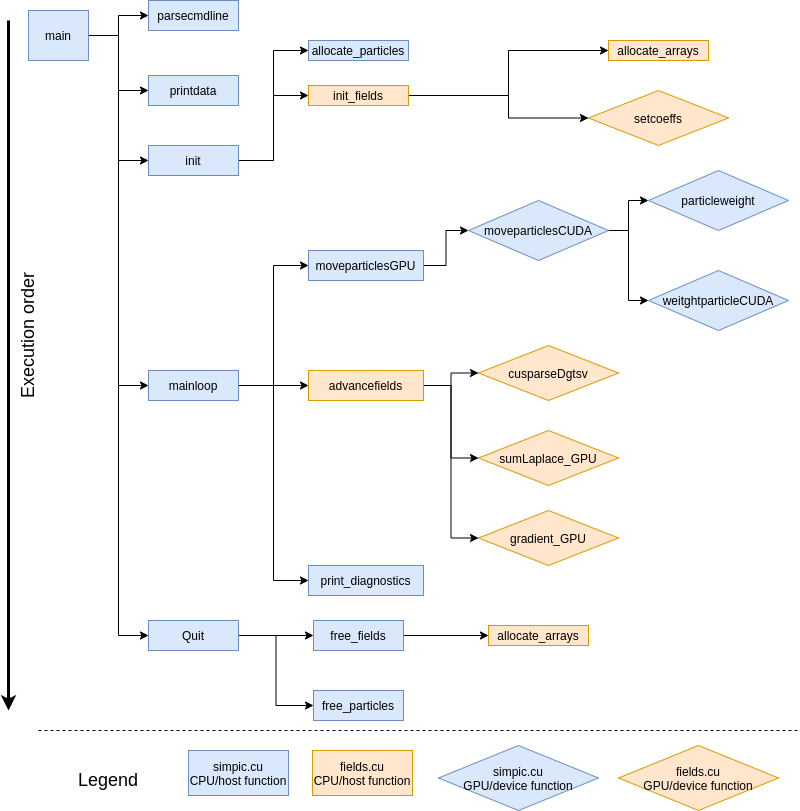
Adapting the PIC code to run in GPUs is not an easy task and this is what occupied my time during the last month of SoHPC.
Parallelizing the code
The main simulation depends on two processes which we moved to GPUs:
- Particle mover: Updates each particle position and velocity and calculates the charge density at the grid points generated by the new positions. The CPU code is already independent as position and velocity of particles do not depend on the others. So, in a GPU we accomplish this calculation for each particle in an unique GPU thread which speeds up the code greatly.
- Field solver: With the new charge density, calculates the electric potential is calculated bysolving a tridiagonal matrix and then the electric field is computed. For this process I encountered a new difficulty. I have to calculate the solution of a tridiagonal matrix system that comes from the discretization of the field equations. This is a dependent calculation, so it cannot be easily transferred to a GPU. To solve this problem, I used a basic algebra library from CUDA called cuSPARSE which contains GPU algorithms to sort out these problems. Also, the rest of the field calculations (computing the gradient of the potential to obtain the field values) are independent so, at this point, it was an easy task to implement.

Conclusions
We (my team partners Paddy, Shyam and me) have developed many versions of the PIC code to improve its performance. We have a CUDA (GPU) version, an OpenMP version and a hybrid CPU-GPU version integrated with StarPU. Now we are working in minor aspects of the code and bench marking for each version.
Stay tuned for the new posts, video and final reports to find out how this process has been made in more detail and which version has the best performance. I hope you enjoyed, see you!
