Hello, with this post I would like to give an update about my project and other interesting activities. My current progress is mainly related to exercises for using vectorization and the Xeon Phi co-processors and therefore it would better to talk about the physics involved with my project in a later blog post. Currently I am practicing on using different methods to accelerate scientific workloads on modern processors. I also compare the performance of a dummy application using different compilers and optimization techniques.
Today’s processors feature faster operations over vectors of data. They offer SIMD (Single instruction, multiple data) instructions which means you can instruct the processor to calculate multiple numbers (e.g the addition of 2 vectors of 4 double floating-point numbers) with a single assembly instruction. This is faster because usually in conventional serial programming each data operation requires a single instruction (SISD – Single instruction, single data), and therefore there are more instructions to be processed for the same amount of data.
Traditionally, computer architects have been adding smart mechanisms to the processors to increase performance, apart from improving the manufacturing process and the transistor count it allows. Such smart mechanisms include the implementation of out-of-order execution and prefetchers. Out-of-order execution tries to automatically reorder the last N number of issued instructions to avoid under-utilization of the CPU from pending memory access requests. Prefetching tries to guess and fetch the required data just before they will be accessed to hide the memory latencies. I would say the combination of the two mechanisms could compete the vectorization approach for performance increase, but it is less scalable especially when trying to increase the number of cores on a chip, due to the significant hardware complexity overhead that comes with adaptive mechanisms. It seems that lately, the processor manufacturers favour adding more vector registers and functionality to their chips and it would be very sensible if the software was designed to utilize these registers for better performance. It is important to note that SIMD instructions were already used in GPUs for many years, due to the regular access patterns of the graphics software. The real challenge is to try to exploit vectorization in scientific software either by hand or to help the compiler do it automatically.
During the last week I was also involved in other interesting activities such as a bike trip with Antti, building a time-lapse video of the Jülich sky and leaving for a weekend for my graduation in England.
My apartment is on the top floor of the highest building in the area. It also has big windows that allow me to enjoy the landscape. It also happens that I always carry with me a Raspberry Pi, which is a small Linux computer with endless capabilities. This was the perfect opportunity to program it to make a time-lapse video of a cloudy day here at Jülich. It has been capturing one photograph every 2 minutes for a day and then it has produced the video by using FFMPEG. You can see the resulting video below or a portion of it in the post thumbnail.






")


 .
. into account which we want to decompose. Suppose, k = 7. Then we achieve the following result after 1000 iterations for also randomly chosen starting point matrices G and S.
into account which we want to decompose. Suppose, k = 7. Then we achieve the following result after 1000 iterations for also randomly chosen starting point matrices G and S.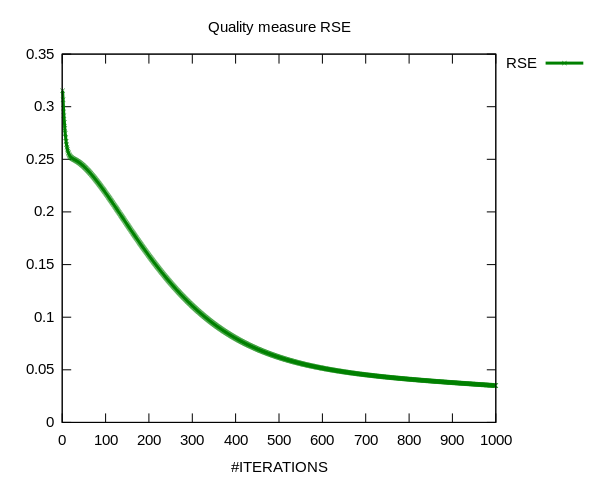






























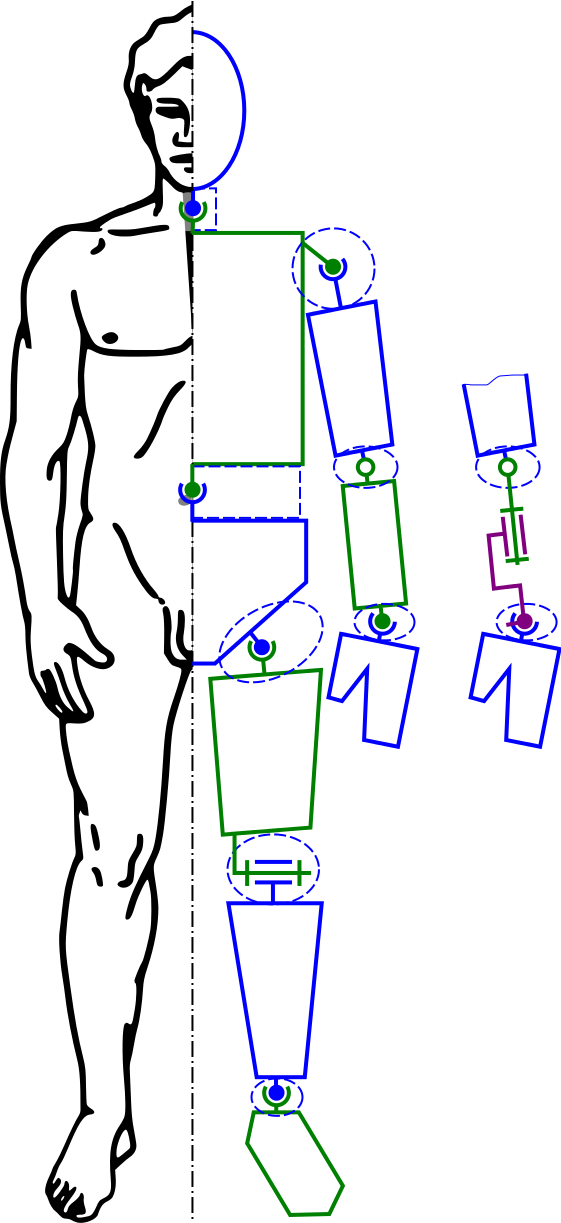

") , which means that it takes a long time to run this algorithm on a large dataset. Thankfully, this algorithm can be parallelised, and a group of researchers at IT4Inovations have implemented a parallel version of this algorithm using OpenMP. This implementation is optimised to run on the Xeon Phi co-processors that are included in several compute nodes of the Salomon cluster. In plain English, this means that this method for generating models of individual bones from the model of the skeleton requires less time to run using the supercomputer.
, which means that it takes a long time to run this algorithm on a large dataset. Thankfully, this algorithm can be parallelised, and a group of researchers at IT4Inovations have implemented a parallel version of this algorithm using OpenMP. This implementation is optimised to run on the Xeon Phi co-processors that are included in several compute nodes of the Salomon cluster. In plain English, this means that this method for generating models of individual bones from the model of the skeleton requires less time to run using the supercomputer.