Hi again!
Welcome to my second post, we are now in the fifth week of the program and everything is going so well for now. They always watch our progress and ready to solve any problems we have faced through.
Coming to the project I am working on. Since the first week, we have been assigned to some tasks and tried to complete them in time duration given to us. In first couple weeks, we studied on Fault Tolerance Interface (FTI) library and did some implementations and tests to get familiar with it. We have also connected to the supercomputer and worked on it. We run our implemented applications on MareNostrum4 and made tests. Then, we discussed about process and decided to search and implement lossy compression and approximate computing techniques on checkpoints and compare them in next step. Firstly, we searched and prepared a presentation about topics, me on approximate computing and my project mate Thanos Kastoras on lossy compression. Next, in last and this weeks, we are working on implementing selected strategies to the library.
In my first post, which is here in case you haven’t read it yet, I have mentioned about the project generally. Now, let me tell a bit deeper.
FTI is application-level checkpointing which allows users to select datasets to protect for efficiency in case of space, time and energy. There are different checkpoint levels which are:
Level 1: Local checkpoint on the nodes. Fast and efficient against soft and transient errors.
Level 2: Local checkpoint on the nodes + copy to the neighbor node. Can tolerate any single node crash in the system.
Level 3: Local checkpoint on the nodes + copy to the neighbor node + RS encoding. Can tolerate correlated failures affecting multiple nodes.
Level 4: Flush of the checkpoints to the Parallel File System (PFS). Tolerates catastrophic failures such as power failures.
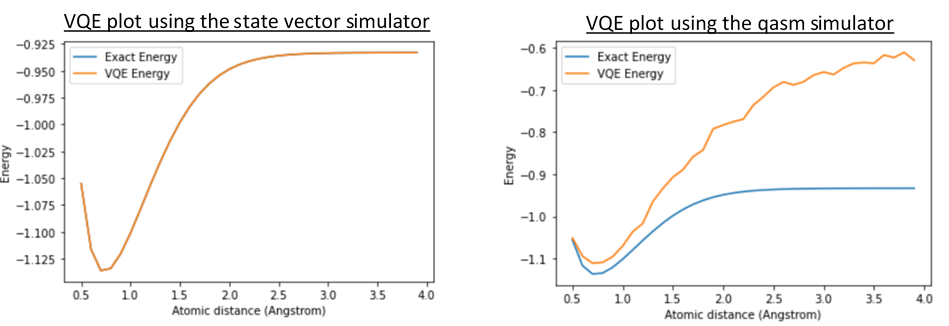
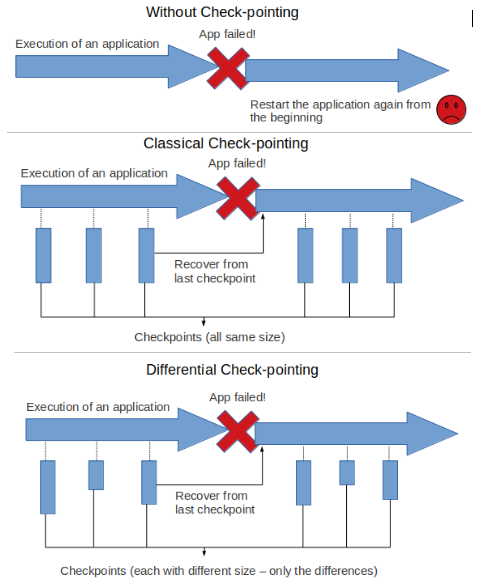
There is also one for differential checkpoint (dcp) which is L4-dcp. In differential checkpointing, only the differences from the previous one are held in checkpoints, thus decreasing the space usage. The difference between without checkpoint, classical checkpoint and differential checkpoint mechanisms can be seen in the simplified figure above.
Now, let me tell a bit about important functions which should be implemented in the application to provide FTI.
Firstly, at the beginning of the code FTI_Init(const char *configFile, MPI_Comm globalComm) function should be placed which initializes FTI context and prepares heads to wait for checkpoints. It takes two parameters which are FTI configuration file and main MPI communicator of the application.
Then, user should use FTI_Protect(int id, void *ptr, int32_t count, fti_id_t tid) to protect, store the data during a checkpoint and load during a recovery in case of a failure. It stores a pointer to a data structure, its size, its ID, its number of elements and the type of the elements.
There are two functions to provide checkpointing. When using FTI_Snapshot(), it makes a checkpoint by given time and also recovers data after a failure and it takes information about checkpoint level, interval etc. from configuration file. But when using FTI_Checkpoint(int id, int level), which level to use should be given as parameter. This function writes down the checkpoint data, creates the metadata and the post-processing work and as it is only for checkpointing before using this function, there are two functions to add for recovery part which are FTI_Status() that returns the current status of the recovery flag and FTI_Recover() function which loads the checkpoint data from the checkpoint file and updates some basic checkpoint information. These functions allow to see if there is a failure and start recovery if that is the case.
Finally, after all is done, FTI_Finalize() should be used to close FTI properly on the application processes.
These were some of important functions to implement FTI to an application and if you are seeking for more information, you can find it here.
Coming to the new functions we would add to the library:
Approximate computing promises high computational performance combined with low resource requirements like very low power and energy consumption. This goal is achieved by relaxing the strict requirements on accuracy and precision and allowing a deviating behavior from exact boolean specifications to a certain extent.
Checkpoints store a subset of the application’s state but sometimes reductions in checkpoint size are needed. Lossy compression can reduce checkpoint sizes significantly and it offers a potential to reduce computational cost in checkpoint restart technique.
That is all for now, I will tell more about precision based differential checkpointing which is the functionality I am trying to implement right now in my next post.
Hope you all a great day!