- Muhammad Omer
- Cem Oran
- Neli Sedej
- George Katsikas
- Seán McEntee
- Cathal Maguire
- Aisling Paterson
- Stefan Popov
- Nathan Byford
- Roberto Rocco
- Petar Đekanović
- Jerónimo Sánchez García
- Irem Kaya
- Alexander Julian Pfleger
- Antonios-Kyrillos Chatzimichail
- Busenur Aktilav
- Berker Demirel
- Andres Vicente Arevalo
- Marco Mattia
- Denizhan Tutar
- Aitor López Sánchez
- Anssi Tapani Manninen
- Josip Bobinac
- Igor Abramov
- Benedict Braunsfeld
- Sara Duarri Redondo
- Pablo Antonio Martínez Sánchez
- Theresa Vock
- Francesca Schiavello
- Ömer Faruk Karadaş
- Davide Crisante
- Nursima ÇELİK
- Elman Hamdi
- Jesús Molina Rodríguez de Vera
- Cathal Corbett
- Joemah Magenya
- Paddy Cahalane
- Víctor González Tabernero
- Shyam Mohan Subbiah Pillai
- İrem Naz Çoçan
- Carlos Alejandro Munar Raimundo
- Shiva Dinesh Chamarthy
- Matthew William Asker
- Rafał Felczyński
- Ömer Bora Zeybek
- Clément Richefort
- Kevin Mato
- Sanath Keshav
- Federico Sossai
- Federico Julian Camerota Verdù
- PRACE Summer of HPC
- About
- FAQ
- Privacy
- History
- 2022
- Blogs 2022
- Youtube videos 2022
- Apply
- Timeline 2022
- Awards 2022
- Projects 2022
- 1. Leveraging HPC to test quality and scalability of a genetic analysis tool
- 2. Fusion reactor materials: Computational modelling of atomic-scale damage in irradiated metal
- 3. Neural networks in chemistry – search for potential drugs for COVID-19
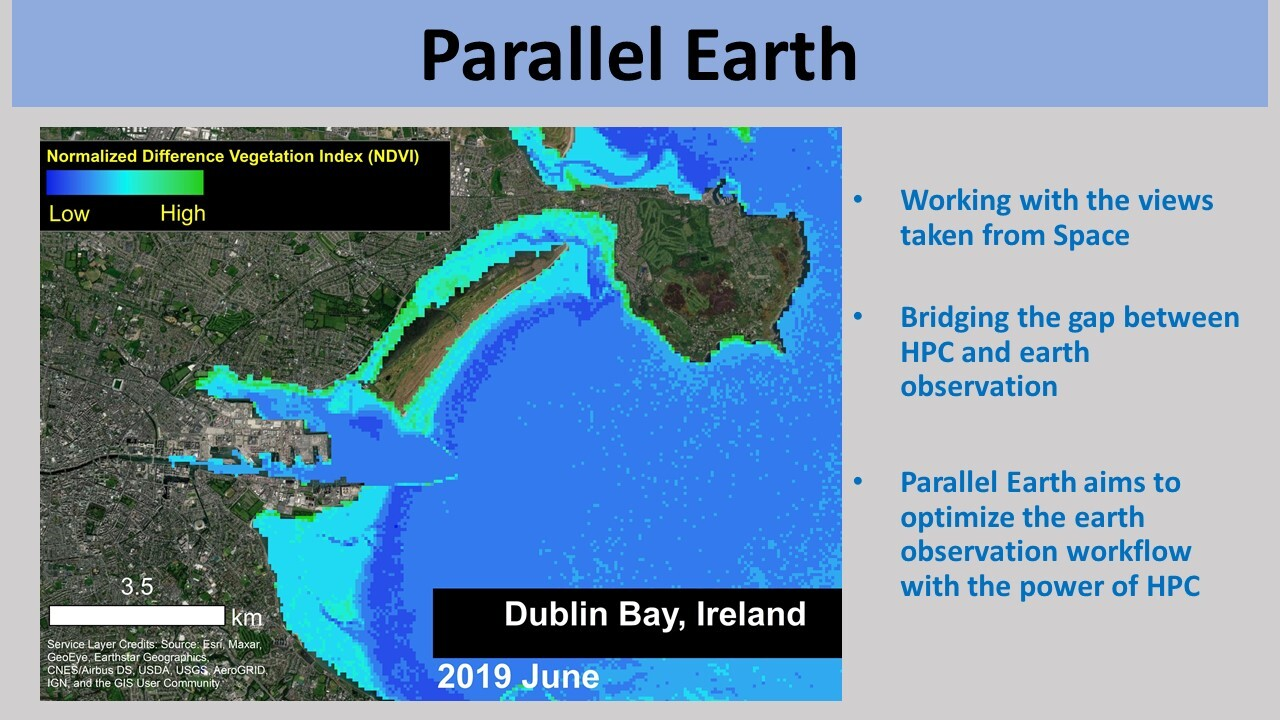
- 4. Automated Extraction of Satellite BAthymetric data by Artificial Intelligence strategies
- 5. A dashboard for on-line assessment of jobs execution efficiency
- 6. Designing a Julia Parallel code for adaptive numerical simulation of a transport problem
- 7. Assessment of the parallel performances of permaFoam up to the tens of thousands of cores and new architectures
- 8. Optimization of neural networks to predict results of mechanical models
- 9. Implementation of an advanced STAbility condition of explicit high-order Spectral Element Method for Elastoacoustics in Heterogeneous media
- 10. Turbulence Simulations with Accelerators
- 11. High Performance Data Analysis: global simulations of the interaction between the solar wind and a planetary magnetosphere
- 12. Fundamentals of quantum algorithms and their implementation
- 13. Heat transport in novel nuclear fuels
- 14. High Performance Quantum Fields
- 15. Chitchat, Gossip & Chatter,- How to efficiently deal with communication
- 16. Scaling HMC on large multi-CPU and/or multi-GPGPUs architectures
- 17. High Performance System Analytics
- 18. Parallel big data analysis within R for better electricity consumption prediction
- 19. Computational Fluid Dynamics
- 20. Performance Comparison and Regression for XDEM Multi-Physics Application
- 21. Designing Scientific Applications on GPUs
- 22. HPC-Derived Affinity Enhancement of Antiviral Drugs
- Participants 2022
- 2021
- Timeline 2021
- 2021 Reports
- Apply 2021
- Summer of HPC 2021 winners
- SoHPC 2021 participants
- Projects 2021
- 1. Analysis of data management policies in HPC architectures
- 2. Computational atomic-scale modelling of materials for fusion reactors
- 3. Precision based differential checkpointing for HPC applications
- 4. Building Resilient Machine Learning Applications (From HPC to Edge)
- 5. Cross-Lingual Transfer learning for biomedical texts
- 6. Improvement of a python package to provide multiple standardized interpolation methods for atmospheric chemistry models
- 7. Neural networks in quantum chemistry
- 8. Efficient Fock matrix construction in localized Hartree-Fock method
- 9. Benchmarking HEP workloads on HPC facilities
- 10. High Throughput HEP Data Processing at HPC
- 11. Automated Classification for Mapping submarine structures by Artificial Intelligence strategies
- 12. Combining Big-data, AI and 3D visualization for datacentre optimization
- 13. Investigating Scalability and Performance of MPAS Atmosphere Model
- 14. Re-engineering and optimizing Software for the discovery of gene sets related to disease
- 15. Performance of Parallel Python Programs on ARCHER2
- 16. Parallel anytime branch and bound algorithm for finding the treewidth of graphs
- 17. Parallelizing Earth Observation Workflow
- 18. Molecular Dynamics on Quantum Computers
- 19. Quantum algorithms and their applications
- 20. High Performance Quantum Fields
- 21. Tiny, tiny, tasks! Huge Impact?
- 22. Numerical simulation of Boltzmann-Nordheim equation
- 23. Parallel radiative heat exchange solver for analyzing samples from the OSIRIS-REx space exploration mission
- 24. Hybrid AI Enhanced Monte Carlo Methods for Matrix Computation on Advanced Architectures
- 25. Scaling HMC on large multi-CPU and/or multi-GPGPUs architectures
- 26. Benchmarking Scientific Software for Computational Chemistry in the Dutch National Supercomputer
- 27. Maximising data processing efficiency in the cloud, with a twist for Research Data Management
- 28. S-gear geometry generation and optimisation algorithm based on transient finite element mechanical/contact analyses
- 29. Big data management for better electricity consumption prediction
- 30. Designing Scientific Applications on GPUs
- 31. Aerodynamics
- 32. HPC Implementation of Molecular Surfaces
- 33. The convergence of HPC and Big Data/HPDA
- Blogs 2021
- Projects 2021
- Youtube presentations 2021
- 2020
- Timeline 2020
- Awards 2020
- Apply 2020
- SoHPC 2020 participants
- Participants 2020 tags
- Blogs 2020
- Projects 2020
- 1. High-performance machine learning
- 2. Neural networks in quantum chemistry
- 3. Visualization of supernova explosions in a magnetised inhomogeneous ambient environment
- 4. Anomaly detection of system failures on HPC accelerated machines using Machine Learning Techniques
- 5. Charm++ Fault Tolerance with Persistent Memory
- 6. Porting and benchmarking on a fully ARM-based cluster
- 7. Performance of Parallel Python Programs on New HPC Architectures
- 8. GPU acceleration of Breadth First Search algorithm in applications of Social Networks
- 9. Object Detection Using Deep Neural Networks – AI from HPC to the Edge
- 10. Development of visualization tool for data from molecular simulations
- 11. High Performance Quantum Fields
- 12. Got your ducks in a row? GPU performance will show!
- 13. Quantum Genome Pattern Matching using Rigetti’s Forest API
- 14. Matrix exponentiation on GPU for the deMon2k code
- 15. Machine Learning for the rescheduling of SLURM jobs
- 16. Scaling the Dissipative Particle Dynamic (DPD) code, DL_MESO, on large multi-GPGPUs architectures
- 17. Benchmarking and performance analysis of HPC applications on modern architectures using automating frameworks
- 18. Time series monitoring of HPC job queues
- 19. Implementing task based parallelism for plasma kinetic code
- 20. Implementation of Paralllel Branch and Bound algorithm for combinatorial optimization
- 21. Submarine Computational Fluid Dynamics
- 22. Novel HPC Parallel Programming Models for Computing (both in CPU and GPU)
- 23. Improved performance with hybrid programming
- 24. Marching Tetrahedrons on the GPU
- Projects 2020
- 1. High-performance machine learning
- 2. Neural networks in quantum chemistry
- 3. Visualization of supernova explosions in a magnetised inhomogeneous ambient environment
- 4. Anomaly detection of system failures on HPC accelerated machines using Machine Learning Techniques
- 5. Charm++ Fault Tolerance with Persistent Memory
- 6. Porting and benchmarking on a fully ARM-based cluster
- 7. Performance of Parallel Python Programs on New HPC Architectures
- 8. GPU acceleration of Breadth First Search algorithm in applications of Social Networks
- 9. Object Detection Using Deep Neural Networks – AI from HPC to the Edge
- 10. Development of visualization tool for data from molecular simulations
- 11. High Performance Quantum Fields
- 12. Got your ducks in a row? GPU performance will show!
- 13. Quantum Genome Pattern Matching using Rigetti’s Forest API
- 14. Matrix exponentiation on GPU for the deMon2k code
- 15. Machine Learning for the rescheduling of SLURM jobs
- 16. Scaling the Dissipative Particle Dynamic (DPD) code, DL_MESO, on large multi-GPGPUs architectures
- 17. Benchmarking and performance analysis of HPC applications on modern architectures using automating frameworks
- 18. Time series monitoring of HPC job queues
- 19. Implementing task based parallelism for plasma kinetic code
- 20. Implementation of Paralllel Branch and Bound algorithm for combinatorial optimization
- 21. Submarine Computational Fluid Dynamics
- 22. Novel HPC Parallel Programming Models for Computing (both in CPU and GPU)
- 23. Improved performance with hybrid programming
- 24. Marching Tetrahedrons on the GPU
- Timeline 2020
- Reports 2020
- 2019
- Apply 2019
- Participants 2019
- Podcasts 2019
- Blogs 2019
- Reports 2019
- Award ceremony 2019
- Projects 2019
- 1. Analysing effects of profiling in heterogeneous memory data placement
- 2. Reproducing Automated Heterogeneous Memory Data Distribution Literature Results and Beyond
- 3. High-performance machine learning
- 4. Electronic structure of nanotubes by utilizing the helical symmetry properties: The code optimization
- 5. IN SItu/Web visualizatioN of CFD Data Using OpenFOAM
- 6. Anomaly detection of system failures on HPC machines using Machine Learning Techniques
- 7. Parallel Computing Demonstrators on Wee ARCHIE
- 8. Performance of Python programs on new HPC architectures
- 9. Task-based models on steroids: Accelerating event driven task-based programming with GASNet
- 10. Using HPC to investigate the structure and dynamics of a KRAS oncogenic mutant
- 11. HPC application for candidate drug optimization using free energy perturbation calculations
- 12. Hybrid Monte Carlo/Deep Learning Methods for Matrix Computation on Advanced Architectures
- 13. Scaling the Dissipative Particle Dynamic (DPD) code, DL_MESO, on large multi-GPGPUs architectures
- 14. Dynamic Deep Learning Inference on the Edge
- 15. Distributed Memory Radix Sort
- 16. Computational Fluid Dynamics Simulations of Formula Student Car Using HPC
- 17. Object Detection Using Deep Neural Networks – AI from HPC to the Edge
- 18. Good-bye or Taskify!
- 19. High Performance Lattice Field Theory
- 20. Encrypted volumes for PCOCC private clusters
- 21. Large scale data techniques for research in ecology
- 22. Visualization schema for HPC gyrokinetic data
- 23. Industrial Big Data analysis with RHadoop
- 24. Energy Reporting in Slurm Jobs
- 25. Performance analysis of Distributed and Scalable Deep Learning
- Timeline 2019
- 2018
- Summer of HPC 2018 participants
- 2018 Reports
- Timeline 2018
- Apply 2018
- Training Week at Edinburgh
- SoHPC 2018 presentations on YouTube
- Award ceremony 2018
- Projects 2018
- 1. Adaptive multi-partitioning for the parallel solution of PDEs
- 2. Automatic Frequency Scaling for Embedded Co-processor Acceleration
- 3. Dynamic management of resources simulator
- 4. Get more throughput, resize me! A case of study: LAMMPS malleable
- 5. Enabling lattice QCD simulations on GPUs
- 6. Multithreading the Multigrid Solver for lattice QCD
- 7. Electronic structure of nanotubes by utilizing the helical symmetry properties: The code parallelization.
- 8. Machine learning from the HPC perspective
- 9. In Situ/Web Visualization of CFD Data Using OpenFOAM
- 10. Web Visualization and Data Analysis of energy Load of an HPC system
- 11. An alert system analysing data from environmental sensors
- 12. Discrete event scheduling simulator for HPC systems
- 13. Parallel Computing Demonstrators on Wee ARCHIE
- 14. High throughput Virtual Screening to discover novel drug candidates
- 15. Investigating the effect of the oncogenic mutation E545K of the PI3Ka protein with enhanced sampling MD simulations
- 16. High-level Visualizations of Performance Data
- 17. Improving existing genomic tools for HPC infrastructure
- 18. GraPhine meets CudeCD
- 19. One kernel to rule them all
- 20. Hybrid-parallel Convolutional Neural Network training
- 21. Large scale accelerator enabled quantum simulator
- 22. Big Data classification with RHadoop
- 23. Visualization schema for HPC data
- 2017
- Timeline
- PRACE Summer of HPC 2017 Training Week
- 2017 Reports
- Summer of HPC awards ceremony 2017
- Project presentations on YouTube
- Projects 2017
- 1. Hybrid Monte Carlo Method for Matrix Computation on P100 GPUs
- 2. Monte Carlo and Deep Learning Methods for Enhancing Crowd Simulation
- 3. Apache Spark: Are Big Data tools applicable in HPC?
- 4. Calculation of nanotubes by utilizing the helical symmetry properties
- 5. Web visualization of Energy load of an HPC system
- 6. Web visualization of the Mediterranean Sea
- 7. Development and validation of real-time earthquake hazard models
- 8. Interactive weather forecasting on supercomputers as a tool for education
- 9. Online visualisation of current and historic supercomputer usage
- 10. Visualizing European Climate Change
- 11. European climate model simulations
- 12. “El-Nino: It’s periodicity and impact on world weather”
- 13. Radiosity in Computer Graphics
- 14. Visualization of real motion of human body based on motion capture technology
- 15. Performance visualization for bioinformatics pipelines
- 16. Cude colors on a phine grid
- 17. Hip, hip, hooray! Get your 2-for-1 GPU deal now.
- 18. Accelerating climate kernels
- 19. Tracing in 4D data
- 20. Parallel algorithm for non-negative matrix tri-factorization
- 21. CAD data extraction for CFD simulation
- Students’ introduction on YouTube
- Participants 2017
- Mr. Anton Lebedev
- Mr. Aleksander Wennersteen
- Mr. Adrián Rodríguez Bazaga
- Mr. Andreas Neophytou
- Mr. Petr Stehlík
- Mr. Arnau Miro Jane
- Mrs. Dimitra Anevlavi
- Mr. Sam Green
- Mr. Jakub Piotr Nurski
- Mrs. Edwige Pezzulli
- Mr. Mahmoud Elbattah
- Ms. Ana Maria Montero Martinez
- Mr. Jamie Quinn
- Mr. David John Bourke
- Ms. Shukai Wang
- Mr. Philippos Papaphilippou
- Mr. Antti Oskari Mikkonen
- Mr. Konstantinos Koukas
- Mr. Alessandro Marzo
- Mr. Jan Packhäuser
- Mr. Paras Kumar
- Training week agenda
- Flyer 2017
- Apply 2017
- 2016
- Projects 2016
- 1. Visualization data pipeline in PyCOMPSs/COMPSs
- 2. Development of sample application in PyCOMPSs/COMPSs
- 3. Topological susceptibility by direct calculation of the eigenmodes
- 4. Mixed-precision linear solvers for lattice QCD
- 5. Calculation of nanotubes by utilizing the helical symmetry properties
- 6. Apache Spark: Bridge between HPC and Big Data?
- 7. In Situ or BAtch VIsualization of biogeochemical state of the Mediterranean Sea
- 8. In Situ VIsualizzation of NAvier-Stokes Tornado Effect
- 9. Parallelising Scientific Python applications
- 10. Weather forecasting for outreach on Wee Archie supercomputer
- 11. Smartphone Task Farm
- 12. Re-ranking Virtual Screening results in computer-aided drug design
- 13. Molecular Dynamics simulation of the E545K PI3Ka mutant
- 14. Visualisation of fluids and waves
- 15. Development of a Performance Analytics Dashboard
- 16. Visualization of real motion of human body based on motion capture technology
- 17. Journey to the centre of the human body
- 18. Shape up or ship out – You decide!
- 19. Phine quarks and cude gluons
- 20. The CFD devil is in CAD details
- 21. Link prediction in large-scale networks with Hadoop framework
- 2016 Reports
- Application form
- Blogs 2016
- Participants 2016
- Training Week
- Training week timetable
- YouTube presentations
- Summer of HPC 2016 reports
- Apply 2016
- Awards Ceremony at Cineca
- Timeline 2016
- Projects 2016
- 2015
- 2014
- 2013
- 2022
- Final Reports